
嗯?小透明上次好像说过要用 C 语言实现的 Huffman 编码进行压缩文件的操作吧?(´っω・。`)
不会咕咕咕的,因为已经做出来惹~/( ˙ ꒳ ˙ )>\
用 C 语言实现 Huffman 编码的做法在上一篇里已经说明得差不多了,本次踩的一些坑,基本上是在文件读写方面……
懒得找新的题图了,就继续用上次的吧
自动读取字符集
严格来说,这里的“字符集”应该叫“字节集”才对~原来书上举例都是用“ABCD”这些字母,不过现在是对文件进行操作,编码的对象就应该是 0x00 到 0xFF 的二进制数据了( ´▽` )ノ
进行 Huffman 编码,需要读取字符和它们各自的权值作为编码依据。之前的作业只要求手动输入字符集和权值,不过面对一个有较大数据量的文件,手动输入显然是不现实的。所以需要通过读取一遍文件,自动对字符和权值进行统计,其中权值就是字节在文件中出现的次数。
先建立一个有 256 个元素的大数组,数组的下标代表字节,下标对应元素的值就可以用来记录字节出现的次数了~不过,一开始我还是这么写的:
//从文件中读取字节集信息
//fp为读取的文件,字节种类数存在size,每个字节和它的出现次数存在set和weight
void LoadByteSet(FILE *fp, unsigned int *size, unsigned char **set, unsigned int **weight) {
//先为0x00到0xFF的字节分配计数用存储空间,下标就是对应字节在文件中出现的次数
unsigned int *FullWeight = calloc(256, sizeof(unsigned int));
while(!feof(fp)) {
FullWeight[fgetc(fp)]++;
}
//中间过程略
free(FullWeight);
}好像没什么问题,不过进行到最后的 free() 这里就报错了?!
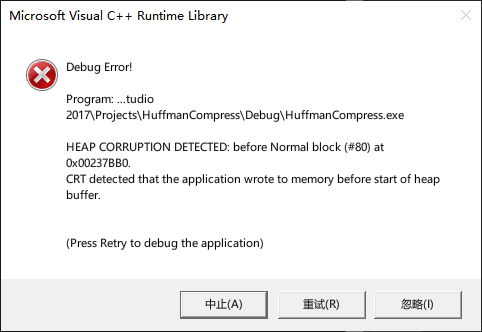
尝试着查了一下这个“before Normal block”的报错信息,结果整个 Stack Overflow 上都只有对于“after Normal block”的讨论,后面这个是使用 malloc() 分配内存进行操作但是空间不足(进行操作的位置在分配的内存后面)的时候经常会碰到的错误。

一开始小透明以为是 fgetc() 返回值类型的问题,毕竟这个函数返回的是 int 而不是一字节的 (unsigned) char。所以先加了个强制类型转换:
while(!feof(fp)) {
FullWeight[(unsigned char)fgetc(fp)]++;
}之后再 free() 就没有报错了,但是字节出现次数的统计中居然多出了一个 0xFF?看来是还没有从本质上解决问题(°ー°〃)
实际上,在读取到文件末尾的时候,fgetc() 不能继续读出字符,会返回一个 0xFFFFFFFF,然后才会修改 fp 使 feof(fp) 为真。先前的做法中,这个时候执行的就是 FullWeight[0xFFFFFFFF]++,所以是哪个字节自增了呢……总之不是分配的内存范围内就是了(•́ω•̀ ٥) 加上了强制类型转换以后,0xFFFFFFFF 被截断为 0xFF,会被当成是读取了 0xFF 这个字节,也会对统计结果造成影响。
使用一个 For 循环,将文件大小作为循环结束的依据,就轮不到最后这个 0xFFFFFFFF 来捣乱了:
//获取文件大小
fseek(fp, 0L, SEEK_END);
unsigned long long FileSize = ftell(fp);
fseek(fp, 0L, SEEK_SET);
for (unsigned long long i = 0; i < FileSize; i++) {
FullWeight[fgetc(fp)]++;
}
//也可以用一个int类型的变量先接住fgetc()的返回值,如果返回值是0xFFFFFFFF就结束循环把所有字节的出现次数统计完了,是不是就可以直接拿着这个有 256 个元素的大数组去生成 Huffman 树了呢?虽然这样也没关系,不过所有字节中可能会有一些出现次数为 0 的字节,它们也会对生成的编码造成影响……
有两个字符集,字符出现的比例分别是 A:B:C:D = 7:0:2:3 和 A:C:D = 7:2:3,去掉根本不会出现的字符 B 实际上是一样的。现在对它们分别求 Huffman 树和编码表:
(为了能直观看出差别,小透明手动用字符把树画出来了_(•̀ω•́ 」∠)_ 如果你的设备不是用等宽字体显示这里的代码的话,示意图大概就会乱掉吧……)
A:B:C:D = 7:0:2:3的H树:
0 w: 0 p: 0 lc: 0 rc: 0
1 w: 7 p: 7 lc: 0 rc: 0
2 w: 0 p: 5 lc: 0 rc: 0
3 w: 2 p: 5 lc: 0 rc: 0
4 w: 3 p: 6 lc: 0 rc: 0
5 w: 2 p: 6 lc: 2 rc: 3
6 w: 5 p: 7 lc: 4 rc: 5
7 w: 12 p: 0 lc: 1 rc: 6
12
/ \
(A)7 5
/ \
(D)3 2
/ \
(B)0 2(C)
字符对应的编码:
A 0
B 110
C 111
D 10
A:C:D = 7:2:3的H树:
0 w: 0 p: 0 lc: 0 rc: 0
1 w: 7 p: 5 lc: 0 rc: 0
2 w: 2 p: 4 lc: 0 rc: 0
3 w: 3 p: 4 lc: 0 rc: 0
4 w: 5 p: 5 lc: 2 rc: 3
5 w: 12 p: 0 lc: 1 rc: 4
12
/ \
(A)7 5
/ \
(C)2 3(D)
字符对应的编码:
A 0
C 10
D 11可以看到,虽然 B 的权为 0,但它仍然“延长”了求编码的路径,结果就是字符 C 的编码被不必要地增加了一个二进制位,这样当然是不好的啊喂!(╯‵□′)╯︵┻━┻
所以我们得从那个数组中去掉没有出现过的字节,再拿去生成 Huffman 编码~这个数组可以当成一个线性表,所以我们要进行的就是删除的操作:删除一项,把之后的每一项都往前挪一点……不行,这样的效率太低了( ‘-‘ )ノ)`-‘ ) 不如“用空间换时间”,再新建一个数组,把出现过的字节和出现次数单独存进去,这个函数也就写完了~
//从文件中读取字节集信息
//fp为读取的文件,字节种类数存在size,每个字节和它的出现次数存在set和weight
void LoadByteSet(FILE *fp, unsigned int *size, unsigned char **set, unsigned int **weight) {
//先为0x00到0xFF的字节分配计数用存储空间,下标就是对应字节在文件中出现的次数
unsigned int *FullWeight = calloc(256, sizeof(unsigned int));
//获取文件大小
fseek(fp, 0L, SEEK_END);
unsigned long long FileSize = ftell(fp);
fseek(fp, 0L, SEEK_SET);
for (unsigned long long i = 0; i < FileSize; i++) {
FullWeight[fgetc(fp)]++;
}
//求出一共出现了多少种字节
*size = 0;
for (unsigned int i = 0x00; i <= 0xFF; i++) {
if (FullWeight[i]) {
(*size)++;
}
}
//输出字节和计数数据
*set = malloc(*size * sizeof(unsigned char));
*weight = malloc(*size * sizeof(unsigned int));
unsigned char *setP = *set;
unsigned int *weightP = *weight;
for (unsigned int i = 0x00; i <= 0xFF; i++) {
if (FullWeight[i]) {
*setP = i;
*weightP = FullWeight[i];
setP++;
weightP++;
}
}
free(FullWeight);
}压缩和解压缩
之前的作业只要求把 Huffman 树保存成一个文件,把编码后的数据保存到另外一个文件。
呐,有哪种压缩文件是除了数据本体还要“拖家带口”的吗?
要解决这个也不难,把 Huffman 树的数据放在文件的前半部分,编码后的数据放在后半部分,这样就可以只输出一个文件了~实际上是把上面两个文件直接合并到一起了( -`ω-)✧
压缩和解压缩的实现和上一篇的描述几乎没什么区别,不过在这里还是先总结一下各自的步骤:
压缩步骤:建 Huffman 树,建编码表,存字符集,存 Huffman 树,存数据
解压步骤:读字符集,读 Huffman 树,建编码表,读数据
以下就是和上次几乎没有什么差别的代码~代码中 DeCompFileName 是未压缩的文件名,CompFileName 是已压缩的文件名。另外小透明还加上了在压缩/解压缩完成后,输出文件压缩率的功能ヾ(•ω•`。)
//压缩部分
//压缩步骤:建树,建表,存字符集,存树,存数据
fopen_s(&fpDeComp, DeCompFileName, "rb");
if (!fpDeComp) {
puts("Input file does not exist.");
return 0;
}
fopen_s(&fpComp, CompFileName, "wb");
LoadByteSet(fpDeComp, &ByteSetSize, &ByteSet, &ByteWeight);
/* 建树建表 */
HuffmanCoding(&HT, &HC, ByteWeight, ByteSetSize);
/* 存字符集 */
fwrite(&ByteSetSize, sizeof(ByteSetSize), 1, fpComp);
fwrite(ByteSet, sizeof(unsigned char), ByteSetSize, fpComp);
fwrite(ByteWeight, sizeof(unsigned int), ByteSetSize, fpComp);
/* 存树 */
fwrite(HT, sizeof(HTNode), 2 * ByteSetSize, fpComp);
/* 存数据 */
fseek(fpDeComp, 0L, SEEK_END);
FileSize = ftell(fpDeComp);
fseek(fpDeComp, 0L, SEEK_SET);
CodeSize = 0;
Offset = 7;
Byte = 0;
//对TextFile中的每个字符进行编码
for (unsigned long long i = 0; i < FileSize; i++) {
fread(&Read, sizeof(char), 1, fpDeComp);
//从编码表中查找对应的编码
for (unsigned int j = 0; j < ByteSetSize; j++) {
if (ByteSet[j] == Read) {
pCode = HC[j + 1];
while (*pCode) {
CodeSize++;
WriteBit(&Byte, Offset, *pCode - '0');
if (Offset) {
//字节没有写满,offset-1
Offset--;
} else {
//字节写满了就写入文件,然后清空字节
Offset = 7;
fwrite(&Byte, sizeof(unsigned char), 1, fpComp);
Byte = 0;
}
pCode++;
}
break;
}
}
}
//最后一个字节没有写满也要写入,没有写满的位都是0
if (Offset != 7) {
fwrite(&Byte, sizeof(unsigned char), 1, fpComp);
}
//在文件最后写入编码位数
fwrite(&CodeSize, sizeof(unsigned long long), 1, fpComp);
/* 输出文件大小,统计压缩比 */
fseek(fpDeComp, 0L, SEEK_END);
InputSize = ftell(fpDeComp);
fseek(fpComp, 0L, SEEK_END);
OutputSize = ftell(fpComp);
printf("Input (Source): %lld Bytes\nOutput (Compressed): %lld Bytes\nCompression ratio: %.2lf%%", InputSize, OutputSize, (double)OutputSize / (double)InputSize * (double)100);
fclose(fpDeComp);
fclose(fpComp);//解压部分
//解压步骤:读字符集,读树,建表,读数据
fopen_s(&fpComp, CompFileName, "rb");
if (!fpComp) {
puts("Input file does not exist.");
return 0;
}
fopen_s(&fpDeComp, DeCompFileName, "wb");
/* 读字符集 */
fread(&ByteSetSize, sizeof(unsigned int), 1, fpComp);
ByteSet = malloc(ByteSetSize * sizeof(unsigned char));
ByteWeight = malloc(ByteSetSize * sizeof(unsigned int));
fread(ByteSet, sizeof(unsigned char), ByteSetSize, fpComp);
fread(ByteWeight, sizeof(unsigned int), ByteSetSize, fpComp);
/* 读树 */
HT = malloc(2 * ByteSetSize * sizeof(HTNode));
fread(HT, sizeof(HTNode), 2 * ByteSetSize, fpComp);
/* 建表 */
InitHuffmanCode(&HC, HT, ByteSetSize);
/* 读数据 */
Index = 2 * ByteSetSize - 1;
//读取编码位数
fseek(fpComp, -1L * (long)sizeof(unsigned long long), SEEK_END);
fread(&CodeSize, sizeof(unsigned long long), 1, fpComp);
//跳过文件头部保存的字符集和H树的信息
fseek(fpComp, (long)(sizeof(ByteSetSize) + ByteSetSize * (sizeof(unsigned char) + sizeof(unsigned int)) + 2 * ByteSetSize * sizeof(HTNode)), SEEK_SET);
Offset = 7;
fread(&Byte, sizeof(unsigned char), 1, fpComp); //先读取一个字节
//对CodeFile中的每个位进行读取
for (unsigned long long i = 0; i < CodeSize; i++) {
Read = ReadBit(Byte, Offset);
if (Read) {
//读到1就移向右子树
Index = HT[Index].rchild;
} else {
//读到0就移向右子树
Index = HT[Index].lchild;
}
//移到叶子结点就写入字符,同时移回根结点
if (!HT[Index].lchild && !HT[Index].rchild) {
fwrite(&ByteSet[Index - 1], sizeof(unsigned char), 1, fpDeComp);
Index = 2 * ByteSetSize - 1;
}
if (Offset) {
//字节没有读完,offset-1
Offset--;
} else {
//字节读完了就读下一个字节
Offset = 7;
fread(&Byte, sizeof(unsigned char), 1, fpComp);
}
}
/* 输出文件大小,统计压缩比 */
fseek(fpComp, 0L, SEEK_END);
InputSize = ftell(fpComp);
fseek(fpDeComp, 0L, SEEK_END);
OutputSize = ftell(fpDeComp);
printf("Input (Source): %lld Bytes\nOutput (Decompressed): %lld Bytes\nCompression ratio: %.2lf%%", InputSize, OutputSize, (double)InputSize / (double)OutputSize * (double)100);
fclose(fpComp);
fclose(fpDeComp);使用 argc 和 argv[] 读取命令行参数
这一部分的内容和 Huffman 编码没有什么关系,不过既然小透明折腾了一下,那就把相关的内容也写在这里吧~
至少在小透明这里,《数据结构》的作业里除了实现指定操作,还会要求添加一个菜单,比如这样:
-- 线性表的操作演示 --
1 - 插入元素
2 - 删除元素
3 - 输出所有元素的值
4 - 清空线性表
……
0 - 结束
请输入选项:然鹅实际上不少命令行程序的根本就不是通过菜单来选择功能,而是使用一系列的命令行参数(っ’-‘)っ
比如知名的多媒体文件转码工具 FFmpeg 不要提格式工厂这种不遵守开源协议的人间之屑:
ffmpeg -i input.mp4 output.avi-i input.mp4 指定了输入文件,output.avi指定了输出文件。当然还可以输入更多参数,不过小透明折腾的这个压缩文件的小程序不需要做得这么复杂……需要设置的参数只有这些:
- 模式设定:压缩/解压缩,用
compress和decompress表示,也可以用c和d作为缩写~ - 输入文件路径
- 输出文件路径
上学期拿着“谭宝书”学习 C 语言的时候有学到主函数可以写上 argc 和 argv[] 两个参数,分别表示执行程序时命令行参数的数量和内容,这次终于可以用上了~٩(ˊᗜˋ*)و
按照上面的设定,(合法地)执行这个小程序的命令行是以下之一:
HuffmanCompress compress input.bin output.bin
HuffmanCompress c input.bin output.bin
HuffmanCompress decompress input.bin output.bin
HuffmanCompress d input.bin output.bin以空格作为分割,每个参数的内容都存储在 argv[] 这个数组中。另外,参数不符合格式时,不少程序会直接输出参数的格式说明,这里也可以加上这样的功能(・▽・〃) 所以主函数可以写成这样:
int main(int argc, char *argv[]) {
//变量定义略
//argv[0]:程序本体的名字
//argv[1]:操作类型:c/compress为压缩,d/decompress为解压
//argv[2]:输入文件的路径
//argv[3]:输出文件的路径
//argv[1~3]不完整则直接输出使用说明
if (argv[1] && argv[2] && argv[3] && (!strcmp(argv[1], "c") || !strcmp(argv[1], "compress"))) {
DeCompFileName = argv[2];
CompFileName = argv[3];
//压缩部分略
} else if (argv[1] && argv[2] && argv[3] && (!strcmp(argv[1], "d") || !strcmp(argv[1], "decompress"))) {
CompFileName = argv[2];
DeCompFileName = argv[3];
//解压部分略
} else {
//参数不完整则输出使用说明
puts("Compress:");
puts("HuffmanCompress compress <InputPath> <OutputPath>");
puts("HuffmanCompress c <InputPath> <OutputPath>");
puts("");
puts("Decompress:");
puts("HuffmanCompress decompress <InputPath> <OutputPath>");
puts("HuffmanCompress d <InputPath> <OutputPath>");
}
return 0;
}压缩测试
既然做出了压缩程序,当然是要给它投喂各种奇怪的东西进行压缩效果的测试啦~
| 测试文件 | 源文件大小 | 7-Zip 19.00 x64 “极速压缩”大小 | 自制的 Huffman 压缩程序压缩大小 |
|---|---|---|---|
| 埃罗芒阿老师 一至七卷(GB2312 编码) | 1372637 | 644420 (46.95%) | 1032914 (75.25%) |
| 随机生成的一堆 Lorem Ipsum | 277251 | 73445 (26.49%) | 150432 (54.26%) |
| FFmpeg 4.1.1 主程序(win64 Static 版) | 62839296 | 18323223 (29.16%) | 52933128 (84.24%) |
| 赤座灯里的图片 | 223785 | 220656 (98.60%) | 231721 (103.55%) |
| 自压《LoveLive! 2nd Season》NCED「どんなときもずっと」 | 33100729 | 32999590 (99.69%) | 33105300 (100.01%) |
- 因为出现的字节种类较少,英文纯文本的压缩效果好于中文。
- 几乎所有压缩软件都不擅长对已经进行过有损压缩的多媒体文件进行进一步的压缩。
- 自制的这个程序压缩效果被 7-Zip 吊打(;-_-) 不过目前主流的压缩算法结合了字典压缩等多种压缩方法,效果当然会比 Huffman 编码单独进行频率统计好上不少。比如
AAAABBCCCD和CBADACABCA这两个字符串,显然前者比后者可以更充分地被压缩。如果使用 Huffman 编码,由于都是A:B:C:D = 4:2:3:1的比例,压缩的效果是一样的……
完整的源代码在这里了~(*´∀`)
Release 处有编译好的程序本体。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2019/04/13/huffman-file-compressor/