
Hashids 是一个小巧的开源库,几乎所有的编程语言都有相应的实现,可以将一个或多个非负整数编码成看上去比较随机的短字符串。按照官网上的例子,347 可以编码成 yr8,[27, 986] 可以编码成 3kTMd,编码结果会根据初始化时的设置而不同,但只要保持设置相同就可以将编码后的字符串解码恢复成原来的数值。
这类算法一般可以用在数据库的自增 ID 上,如果需要把它写在 URL 或者 API 请求之类的地方展示出来但又不想轻易地被爬虫爬一遍的话……
例如以前屑站使用 AV 号对视频进行编号,实际上也是一个自增 ID,于是写个请求 http://acg.tv/av{i} 的爬虫,然后将 i 的值设为 0、1、2……如此一直爬下去,就可以获取到屑站所有视频的数据。后来屑站实装了 BV 号,av170001 变成了 BV17x411W7Kc,一时看不出规律,写爬虫就不怎么方便了。这个 BV 号就是对 AV 号使用 Hashids 类算法编码的结果。
不过 BV 号实装后没多久就有人翻出了 AV 号和 BV 号互转的算法,并且 AV 号仍然可以照常使用,所以折腾出 BV 号这东西的意义嘛……另外 av99999999 之后的视频的 AV 号就不再自增而是随机生成了,真正起到反爬虫作用的其实是这个才对。
又比如你写了一个论坛,帖子的 ID 一般就是自增的。直接将自增 ID 展示出来的话,所有人都可以很容易地算出这个论坛每天发了多少帖子,由此继续分析用户活跃程度之类的……就像下面这样,注意写着 No. 的地方:
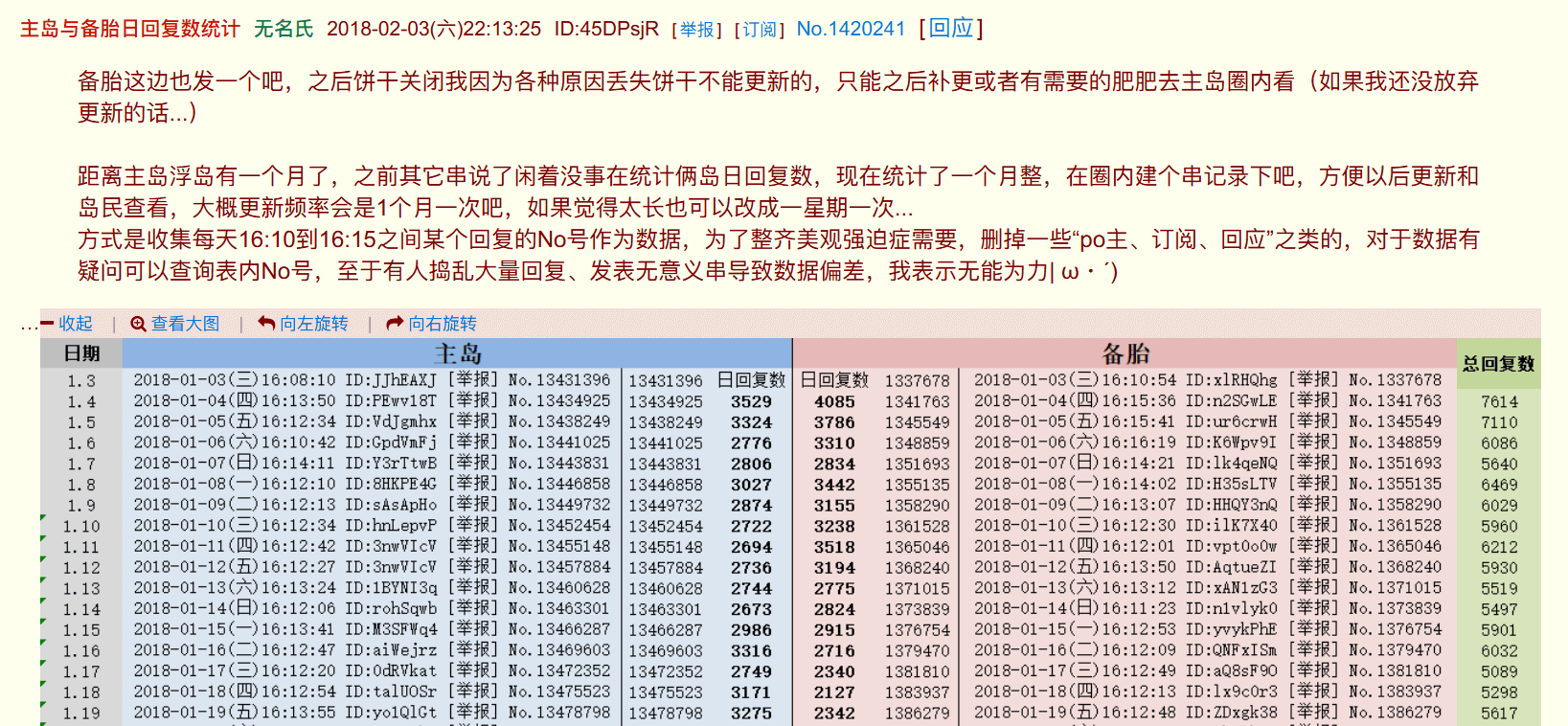
A 岛默许了这个统计,而且使用自增 ID 的串号表示回复和引用本身就是 A 岛社区文化的重要一部分,比叔叔把已是屑站象征之一的 AV 号雪藏掉不知道高到哪里去了。当然对这个串号使用爬虫(又称“爬岛”)还是不允许的。
Hashids 可以自定义编码时用到的字符表(默认是大小写字母数字,但是使用任意 Unicode 字符例如汉字和 emoji 也是可以的),还可以设置编码后字符串的最小长度(默认不设置,设置后编码得到的字符串长度小于此值则会用一定方式填充),另外还有叫 salt 的设定,设置不同的 salt 也会影响编码结果(就像加盐的 hash 算法那样?!)。可以在这里随意尝试~
Hashids 真的属于 hash 算法吗?
虽然 Hashids 的名字里面就写着 hash,而且设置里也用上了 salt 这种确实和 hash 算法有关的词,但是它真的是一个 hash 算法吗……找出 hash 算法的定义来对比一下:
- 给定原始数据,很容易可以计算出对应的 hash 值。显然成立。
- 即使原始数据出现很小的差异,对应的 hash 值也会有巨大的变化,尽量不要产生碰撞。在上面的“随意尝试”里就可以看出确实会产生巨大变化(虽然某些地方的变化并不大……),而且按照 Hashids 的原理(稍后说明)冲突是完全不可能产生的。
- 给定 hash 值,反过来计算原始数据是很难的。嗯?Hashids 编码得到的字符串是可以恢复的啊?
最后一条定义说明了 Hashids 实际上并不是一个严格意义上的 hash 算法。虽然各种真正的 hash 算法(例如 bcrypt 或者各种 HMAC)都有 salt 的设定,但是就算知道了 salt 也很难恢复出原始数据,而 Hashids 的这个 salt 嘛……完全相反,所以它起到的更像是加密算法中密钥的作用。
实际上 Hashids 是使用进制转换的方式对数值进行编码的,将一般的数转换为十进制是固定使用数字 0-9,十六进制是数字 0-9a-f,而 Hashids 要转换到几进制和设置的字符表的长度有关,对每个数的每一位使用的“数字”是根据输入数值和设置的 salt 按照一些规则打乱字符表得到的,所以 Hashids 更像是一种多表代换密码,就像维吉尼亚密码那样,虽然每个字符都使用简单的凯撒密码加密,但是 offset 不同,于是攻击难度稍微提高了。
就算是在这里把 Hashids 当成加密算法,它的强度也不算太高,绝对不是密码学上安全的算法,所以严禁将 Hashids 用于加密机密数据,更不要真的像使用 hash 算法一样把它用于保存密码。按照这里的分析,在使用选择明文攻击、字符表等设置使用默认值但不知道 salt 的情况下,通过解一组方程分析 salt 的前三个字符有大概 200 种可能,这个数量已经大大低于暴力破解需要尝试的次数了。
为什么设计这个算法的人选用了 hash 和 salt 之类的名词?按照官网上的说明,因为对一般人来说,它看起来像 hash,走路像 hash,叫声像 hash,那么它就是……⊂彡☆))д`)
Why “hashids”?
Originally the project referred to generated ids as hashes, and obviously the name hashids has the word hash in it. Technically, these generated ids cannot be called hashes since a cryptographic hash has one-way mapping (cannot be decrypted).
However, when people search for a solution, like a “youtube hash” or “bitly short id”, they usually don’t really care of the technical details. So hashids stuck as a term — an algorithm to obfuscate numbers.

从这里开始就是介绍 Hashids 的比较详细的实现细节了。在此之前我 Google 了一下介绍 Hashids 的文章,基本上都是简单介绍一下它的主要用途是混淆自增 ID,然后就是一大堆复制粘贴的用法示例了,偶尔有几篇提到了“进制转换”不过也并不是很详细……所以接下来我会参考 TypeScript/JavaScript 版实现的源码详细介绍一下编码和解码的原理(其它语言的实现应该也是类似的)。
如果只是想要简单了解 Hashids 原理的话,可以直接阅读官网上的介绍,简略介绍了进制转换等各种涉及到的步骤。想要了解更多细节的话就继续往下翻吧~
算法的初始化
所有的编码和解码都是使用同一个 Hashids 对象的实例,在创建这个实例时进行算法的初始化,一般情况下需要输入以下参数:
- salt:一个可以包含任意字符的字符串,对之后打乱字符表的结果有影响。默认是留空。
- minLength:最小长度,编码得到的字符串长度小于此值则会用一定方式填充。默认是留空。
- alphabet:初始字符表,不能有重复字符,编码结果只可能含有这里的字符,即使字符相同顺序不同也会改变结果,长度至少为 16。默认是
a-zA-Z1234567890一共 62 个字符。 - seps:编码中用于分隔各个数值的字符(稍后说明 x2),必须是 alphabet 的子集,但是不要求字符不重复,顺序也会影响结果。默认是
cfhistuCFHISTU,原作者的想法是使用这些字母做分隔符可以避免编码结果中出现粗鄙之语。
实际上 JS 版实现会自动处理字符表去重、“不能重复”和“子集”之类的要求。
初始化以后就可以进行编码了。
const hashids = new Hashids(
// salt
'@salt!',
// minLength
24,
// alphabet: use default
undefined,
// seps
'SEPS'
);
console.log(hashids.encode(114514, 1919810, 893, 931));
// tY8p8oMWMb76xOS3Jh4uvs2x
console.log(hashids.decode('tY8p8oMWMb76xOS3Jh4uvs2x'));
// [114514, 1919810, 893, 931]编码后的字符串,看上去是一堆没什么规律的字母数字,实际上可以分成几个部分。例如上面得到的字符串 tY8p8oMWMb76xOS3Jh4uvs2x 就可以分为用不同颜色表示的以下部分:
- 单个数值编码后的值
- seperator,也就是不同数值之间的分隔符
- lottery,用于在编码过程中打乱字符表
- guard,用于分隔编码部分和填充部分
- 编码后字符串左右两边的填充
前三个是实际的编码部分,后两个用于填充,只有设置了最小长度的情况下才有可能出现在编码结果中。
Hashids 算法中经常需要打乱字符串中的字符,使用的都是下面这个稍有修改的 Fisher–Yates Shuffle 洗牌算法,除了要打乱的字符串(拆成了包含所有字符的数组)这里还有另一个参数也叫 salt(留空则直接原样返回不打乱),只要字符串和 salt 相同就可以保证打乱结果相同……所以这个 salt 起的明明是随机数生成器中种子的作用吧!(╯‵□′)╯︵┻━┻ 为了不与一开始输入的 salt 混淆,之后就用 seed 表示打乱时的这个 salt 参数好了。
function shuffle(alphabetChars, saltChars) {
if (saltChars.length === 0) {
return alphabetChars;
}
let integer;
const transformed = alphabetChars.slice();
let v = 0;
let p = 0;
for (let i = transformed.length - 1; i > 0; i--) {
// 在原始的Fisher-Yates Shuffled里,j是0-i范围的一个随机数
v %= saltChars.length;
p += integer = saltChars[v].codePointAt(0);
const j = (integer + v + p) % i;
v++;
[transformed[i], transformed[j]] = [transformed[j], transformed[i]];
}
return transformed;
}在上面的例子里,一开始的时候输入了 SEPS 四个字符作为 seps,先从输入的字符表中去掉这几个字符(没有了 E、P、S 这三个大写字母,此时还剩下 62 - 3 = 59 个字符),然后以 salt 作为 seed 将 seps 打乱一次,打乱结果为 SSEP。但是上面的编码结果中还出现了这些字符之外的 seperator(b 和 h),这是因为 Hashids 要求 seps 的字符数量必须不少于字符表长度的 1/3.5(向上取整),所以这里需要 Math.ceil(59 / 3.5) = 17 个字符作为 seps,不足的 13 个字符从字符表的前几个字符中取出来,接到 seps 后面补充数量。
补充之后,最后的 seps 字符列表就是 SSEPabcdefghijklm(后面的 a-m 是从字符表中取出的),字符表是 nopqrstuvwxyzABCDFGHIJKLMNOQRTUVWXYZ1234567890(前面的 a-m 被取走了,还有 59 - 13 - 46 个字符)。
如果设置了编码后字符串的最小长度的话,编码后可能会需要进行填充。Hashids 通过在实际的编码部分左右各放置一个 guard 字符的方式将编码部分和填充部分分开。guards 也是从字符表中取出的,并不能手动设置,字符数量是字符表长度的 1/12(向上取整)。在这里就需要取出 Math.ceil(46 / 12) = 4 个字符。
先以 salt 作为 seed 将当前的字符表打乱一次,字符表变成了 vpnz0xJYw6Q1TLNqH8WGuRB5ZMKOAroCFtD74IU2ysX9V3,然后取出字符表的前 4 个字符 vpnz 作为 guards,字符表中剩下 0xJYw6Q1TLNqH8WGuRB5ZMKOAroCFtD74IU2ysX9V3 一共 42 个字符,这些字符会出现在编码结果的除 seperator 和 guard 以外的所有部分中。
最后用一个流程图来概括以上的初始化过程:

对输入的数进行编码
初始化以后就可以将输入的整数编码了,编码期间使用的字符表 alphabet 是从初始化后的 Hashids 对象里复制的,虽然会涉及多次打乱字符表的操作但是并不会改变原对象的字符表,解码的时候也是一样的。
可能是为了添加更多的随机性,Hashids 算法在编码过程中设置了一个称为 lottery 的字符。对于每个输入的第 a 个数 b(a 是从 0 开始计数的),计算 b % (100 + a) 的和(记为 numbersIdInt,后面还会用到),则 alphabet[numbersIdInt % alphabet.length] 就是 lottery 字符。
在上面的例子中,初始化以后的 alphabet 是 0xJYw6Q1TLNqH8WGuRB5ZMKOAroCFtD74IU2ysX9V3,对 [114514, 1919810, 893, 931] 编码得到的 lottery 是 8 也就是 alphabet[13],是根据以下过程算出的:
114514 % 100 = 141919810 % 101 = 2893 % 102 = 77931 % 103 = 4numbersIdInt = 14 + 2 + 77 + 4 = 97lotteryIndex = 97 % 42 = 13
然后就是对每个数编码了。前面提过 Hashids 的编码原理是进制转换,现在 alphabet 有 42 个字符,相当于将各个数转换为 42 进制。Hashids 又有多表代换的特征,表现在编码每个数之前 alphabet 都会使用 lottery + salt + alphabet 作为 seed 被打乱一次(取代之前的 alphabet),于是每个数在进制转换时使用的“数字”都是不一样的。
如果编码的不是最后一个数,编码后还要添加一个 seperator,计算方法是:对于第 a 个数 b,编码后的第一个字符的 Unicode 码点是 c,则需要添加的 seperator 是 seps[a % (b + c) % seps.length]。
例如,上面的例子中编码的过程:
- 使用 seed
8@salt!0xJYw6Q1TLNqH8WGuRB5ZMKOAroCFtD74IU2ysX9V3打乱字符表得到8ouNLs4OK5V9wA613QqG7XMYZ0JRTFy2BCHItUWxrD - 进制转换的结果是
114514 = 1 * 42 ** 3 + 22 * 42 ** 2 + 38 * 42 ** 1 + 22 * 40 ** 0 - 转换后的各位数
1 22 38 22在字符表中对应的字符分别是 oMWM "o" = String.fromCodePoint(111),所以添加 seperator:seps[114514 % (0 + 111) % 17] = seps[73 % 17] = seps[5]也就是 b- 使用 seed
8@salt!8ouNLs4OK5V9wA613QqG7XMYZ0JRTFy2BCHItUWxrD打乱字符表得到DWsUJ81NVrXqAxtYZ9wuIBG547K2RML3OQTCFH6o0y - 进制转换的结果是
1919810 = 25 * 42 ** 3 + 38 * 42 ** 2 + 13 * 42 ** 1 + 32 * 42 ** 0 - 转换后的各位数
25 38 13 32在字符表中对应的字符分别是 76xO "7" = String.fromCodePoint(55),所以添加 seperator:seps[1919810 % (1 + 55) % 17] = seps[18 % 17] = seps[1]也就是 S- ……
最后可以得到未填充的编码部分 8oMWMb76xOS3Jh4u。
编码结果的填充
如果设置了最小长度,而刚刚得到的编码结果长度又不足,那么就需要进行填充了。Hashids 使用放在编码部分左右两边各一个的 guard 字符将编码和填充部分分开,这两个字符均使用 guards[(numbersIdInt + x) % guards.length] 求出,对于左边/右边的 guard,x 分别是编码部分第 0/1 个字符的 Unicode 码点。先添加左边的 guard,如果已经满足最小长度则不再添加右边的 guard。在上面的例子中:
- guards 是 vpnz
- 编码部分长度 16,前两个字符的 Unicode 码点:
"8" = String.fromCodePoint(56)和"o" = String.fromCodePoint(111) - 设置了最小长度为 24,编码结果的长度不足,因此在左边添加
guards[(97 + 56) % 4] = guards[1]也就是 p - 长度仍然不足,因此在右边添加
guards[(97 + 111) % 4] = guards[0]也就是 v
如果添加 guard 之后长度还是不足呢?接下来就会在编码结果的左右两边填充数遍完整的字符表了。
- 以 alphabet 自己作为 seed 打乱 alphabet(同样是取代之前的 alphabet)
- 将 alphabet 一分为二,前
Math.floor(alphabet.length / 2)个字符添加到编码结果右边,剩下的字符添加到编码结果左边 - 循环到编码结果的长度超过最小长度为止
- 取编码结果 result 的从第
Math.floor((result.length - minLength) / 2)个字符开始的 minLength 个字符作为最后的编码结果
在上面的例子中,添加了 guard 的编码结果是 p8oMWMb76xOS3Jh4uv,打乱一次 alphabet 的结果是 s2xC0oRZAQuLqyK6GwXUHNTB7rV4IOD51MF9WJ3tY8,添加到编码结果的左右两边得到 NTB7rV4IOD51MF9WJ3tY8p8oMWMb76xOS3Jh4uvs2xC0oRZAQuLqyK6GwXUH,长度为 60,于是截取从第 Math.floor((60 - 24) / 2) = 18 个字符开始的 24 个字符,得到最后的编码结果 tY8p8oMWMb76xOS3Jh4uvs2x。
解码和校验
对 Hashids 的解码实际上是把字符串中表示每个数的字符串恢复回原来的数,因为 seps 和 guards 是固定的,lottery 又固定是 guard 之间的未填充的编码部分的第一个字符,所以很容易就可以把每个数的字符串从编码后的字符串里拆出来。按照同样的顺序,每解码一个数之前,先使用 lottery + salt + alphabet 打乱一次字符表,对照字符表得出这个数在 x 进制下的表示,再转换到十进制就可以完成解码了。
既然这样,那剩下的 seperator 和 guard 还有填充部分随便乱写,也是可以解码出结果的哦?
当然不能出这种问题啦!所以 Hashids 的处理方法是……把解码出的数重新编码一遍,如果和输入的字符串不同则按照解码结果无效处理,什么也不返回。
看来这些部分还起到了校验码的作用呢。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2021/02/26/hashids-description/