
在 Windows 系统中 PowerShell 是个好东西,它的地位相当于传统的命令提示符 cmd 的威力加强版。和 cmd 差不多的是,使用 Windows+R 打开“运行”,输入 powershell 然后回车,就可以打开 PowerShell 的命令行窗口开始搞事c(`・ω´・ c)っ
有过面向对象(然鹅小透明自己都没有对象……)编程经验的人熟悉了语法之后应该很快就可以上手 PowerShell,毕竟 PowerShell 本身就是面向对象的脚本语言,用的是 .NET Framework 的那一套东西,但是在此基础之上还内置了很多把对象预先封装好的操作,称为 cmdlet。
比如 Get-ChildItem 就是获取某个目录下的所有文件夹和文件。cmdlet 用起来方便,记起来也方便(一般都是“动词-名词”的命名方式)~
由于这篇废文不应该是 PowerShell 广告文,所以小透明就不在这里继续列举 PowerShell 的优点了……总之是个好东西,小透明自己也经常用,比如用 Get-ChildItem 和 Rename-Item 给文件批量更名什么的(´っω・。`)
想要入门 PowerShell 的话,PowerShell 中文博客是个好地方,这个网站上有一套完整的入门教程~
因为最近使用 PowerShell 的时候实在忍受不了在某些情况下使用 Invoke-WebRequest 下载文件的速度,以及最近又是没有什么事干(“明明忙爆了好吗你还在摸鱼!”),所以就打算自己造一个轮子,尝试在 PowerShell 中实现多线程下载的功能~(๑‾ ꇴ ‾๑)
(末尾处有完整代码的下载)
(已经在 Google 上搜索过 “PowerShell Multithread Download” 了,但是结果都是和多线程有关的,和下载没什么关系)
(轮子是造着玩的,并没有什么错误处理机制,所以有一个线程下载失败的话整个下载就失败了……)
多线程下载原理
一般的单线程下载文件是客户端和服务端建立一个连接,然后一点点地从服务端获取文件数据。
这样的下载理论上来说不应该存在速度限制(当然速度也不可能超过客户端的网速),但是实际情况下由于一些不可抗力,例如网络波动或者是服务端出于节约资源等目的进行限速,下载文件时单个连接常常不能跑满带宽,这时就需要使用多线程建立多个连接进行下载了。
如果将“下载文件”的过程类比成从水缸中抽水的话,单线程和多线程下载的区别,就是使用一台和同时使用多台抽水机的区别ヾ(•ω•`。)
多线程下载的每个线程/连接,下载的是文件的一部分。例如使用八个线程进行下载,每个线程各自下载的就是文件的八分之一。
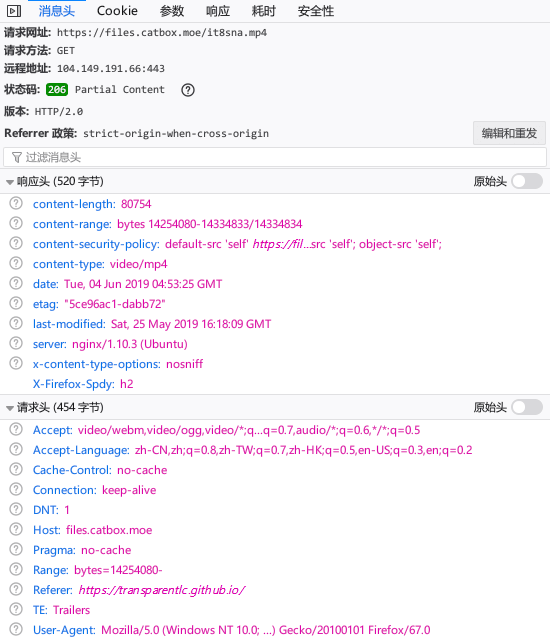
指定每个线程/连接下载一部分文件,需要设定 HTTP 请求头中的 Range 参数,例如 Range: bytes=0-1023 就是仅下载文件中第 0 到 1023 字节的内容。
另外,下载前还需要获取文件的大小。向服务端发送一个 HEAD 类型的请求(和一般使用的 GET 不同的是,HEAD 只返回响应头,不返回响应的内容本体),然后根据响应头中的 Content-Length 参数就可以获取文件大小(以字节为单位)。
使用 Range 的分片下载在浏览器中也有应用。比如网页上有个用 <video> 标签显示的视频,浏览器一般会先加载视频文件的开头一部分,获取视频的元数据。元数据中有视频的总时长,读取后可以显示在进度条上(即使没有播放视频),便于用户直接点击进度条“空降”。
实际上“提前获取元数据”是 <video> 标签的 preload 属性设为 metadata 的效果,这是大多数浏览器设定的默认值。
如图所示:如果用户点击进度条跳转到某一时刻,浏览器也会根据元数据,从某个位置开始加载视频文件,包括了该时刻之后的视频数据。这里的 Range 写的是 bytes=14254080-,没有设定结束的位置,表示加载从第 14254080 字节开始到文件末尾的内容。“断点续传”也使用了类似的原理,根据已下载部分的大小设定继续下载时的起点。
简单来说,多线程下载的一般过程是:
- 向服务端发送
HEAD请求,通过Content-Length获取文件大小,这里以100000为例。 - 计算每个线程下载文件的范围。例如使用四个线程,则每个线程下载的
Range分别是0-25000、25001-50000、50001-75000和75001-。 - 建立线程和连接,开始下载。
- 所有线程下载完毕后,将每个线程下载的部分文件按顺序合并到一起。
分片下载
PowerShell 中直接下载文件使用的是内置的 cmdlet Invoke-WebRequest,还可以用 Header 参数自定义请求头:
Invoke-WebRequest -Uri 'https://files.catbox.moe/sp3axt.mp4' -OutFile 'Eromanga Sensei ED.mp4' -Header @{'key1' = 'value1'; 'key2' = 'value2'}但是 Header 不是可以随便改的……(,,•́.•̀,,)如果修改了某些特定的请求头就会报错,比如修改 User-Agent 是可以的,直接修改 Range 就不行。
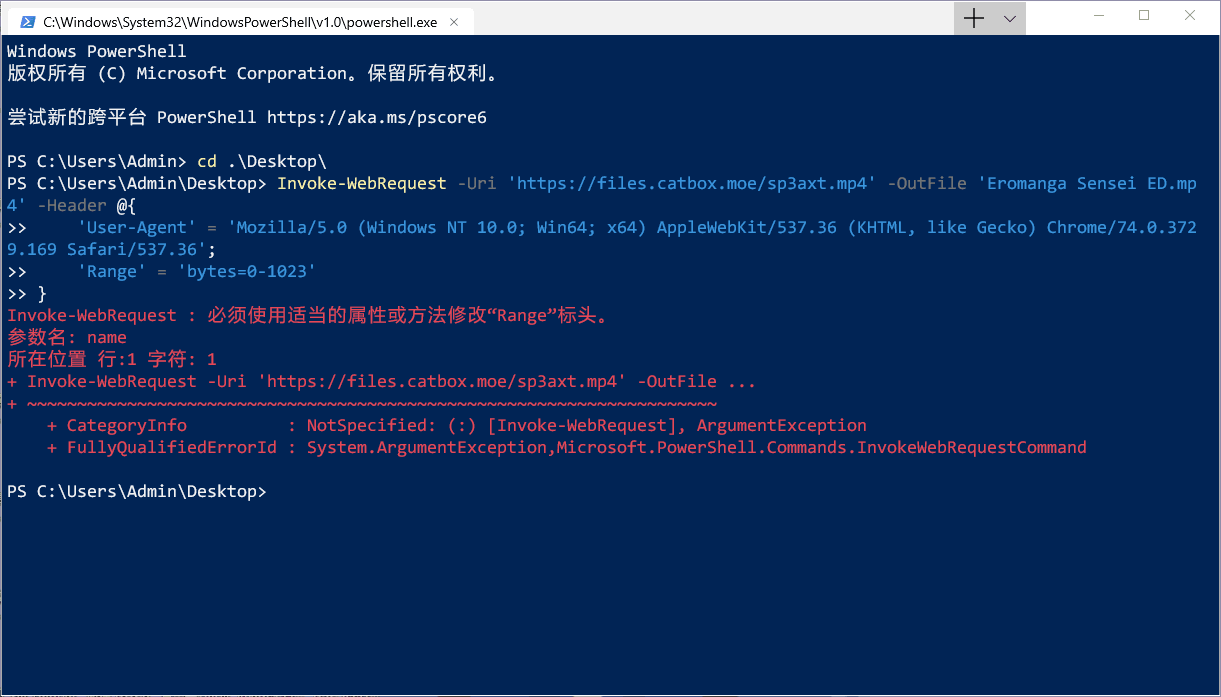
“适当的属性和方法”?难道小透明这么修改不适当吗?(╯‵□′)╯︵┻━┻
Invoke-WebRequest 是对 .NET Framework 中 System.Net.WebRequest 类的一个封装,参数 Header 对应着这个类的属性 Headers,它包括了发出的 HTTP 请求的所有请求头……但是微软的技术文档也写着:
The Headers collection contains the protocol headers associated with the request. The following table lists the HTTP headers that are not stored in the Headers collection but are either set by the system or set by properties or methods.
…
Range: Set by the AddRange method.
总之 Range 是不存储在 Headers 中的,必须特别使用 AddRange(Int64, Int64)这个方法去修改(˘̩̩ε˘̩ƪ)但是 Invoke-WebRequest 是个预先封装好的 cmdlet,并没有准备某个参数可以调用这个方法,这就很尴尬了(摊手
所以 cmdlet 虽然用起来方便,但是扩展性是不够的,这时就只能自己操作 .NET 对象来实现功能了꜀(。௰。 ꜆)꜄
自己操作对象实现文件下载的话,除了指定下载范围,当然还要实现将获取的数据写入文件,不过后者就是很简单的文件读写操作了:从网络获取的文件数据可以视为一个文件流,在本地保存的文件也可以视为一个文件流,使用 CopyTo(Stream) 就可以将获取的数据保存到本地。
“文件流”就是 System.IO.Stream,有点类似于 C 语言中的 FILE *fp = fopen(...);。
以下是完整的函数代码~
# 下载文件的一部分
# [String]$Uri: 下载文件的地址
# [String]$OutFile: 保存文件的路径
# [Int64]$Start [Int64]$End: 下载的范围
# [String]$UserAgent: 下载文件时使用的UA
function PartiallyDownload-File([String]$Uri, [String]$OutFile, [Int64]$Start, [Int64]$End = 0, [String]$UserAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0') {
$Request = [Net.WebRequest]::Create($Uri)
# $End的默认值为0,此时表示下载结束位置为文件末尾
if ($End) {
$Request.AddRange($Start, $End)
} else {
$Request.AddRange($Start)
}
$Request.UserAgent = $UserAgent
# 获取响应和文件流,同时在本地新建一个用于保存的文件,进行复制
$Response = $Request.GetResponse()
$Stream = $Response.GetResponseStream()
$File = [IO.File]::Create($OutFile)
$Stream.CopyTo($File)
# 下载完成后关闭文件和连接
$File.Close()
$Stream.Close()
$Response.Close()
}计算好每个线程下载文件的范围后,就可以使用这个函数让线程开始下载文件了|ω•`)
合并文件
使用 PowerShell 的 cmdlet 和管道操作就可以实现二进制文件的合并:
# 将part1.bin、part2.bin和part3.bin合并到merge.bin
Get-Content -Path 'part1.bin','part2.bin','part3.bin' -Encoding Byte | Set-Content -Path 'merge.bin' -Encoding Byte但是经过小透明的测试,这样太慢了,对于稍微大一点的文件就完全读取不能(。í _ ì。)
有一种改进的方法是设定 Get-Content 的 ReadCount 参数(这参数的默认值居然是 1 ?!)来提升读取文件的速度,每次读取一定大小的数据到内存后,再通过管道让 Set-Content 将读取的数据写入文件~
对了,ReadCount 设为 0 的话就是将整个文件读取到内存。如果要读取大文件的话,只要电脑的内存够大,这么做也不是不可以(逃
Get-Content -Path 'part1.bin','part2.bin','part3.bin' -ReadCount 256KB -Encoding Byte | Set-Content -Path 'merge.bin' -Encoding Byte从桌面上随便找了一个大约 30MB 的文件,测试一下设定了 ReadCount 后的效果:
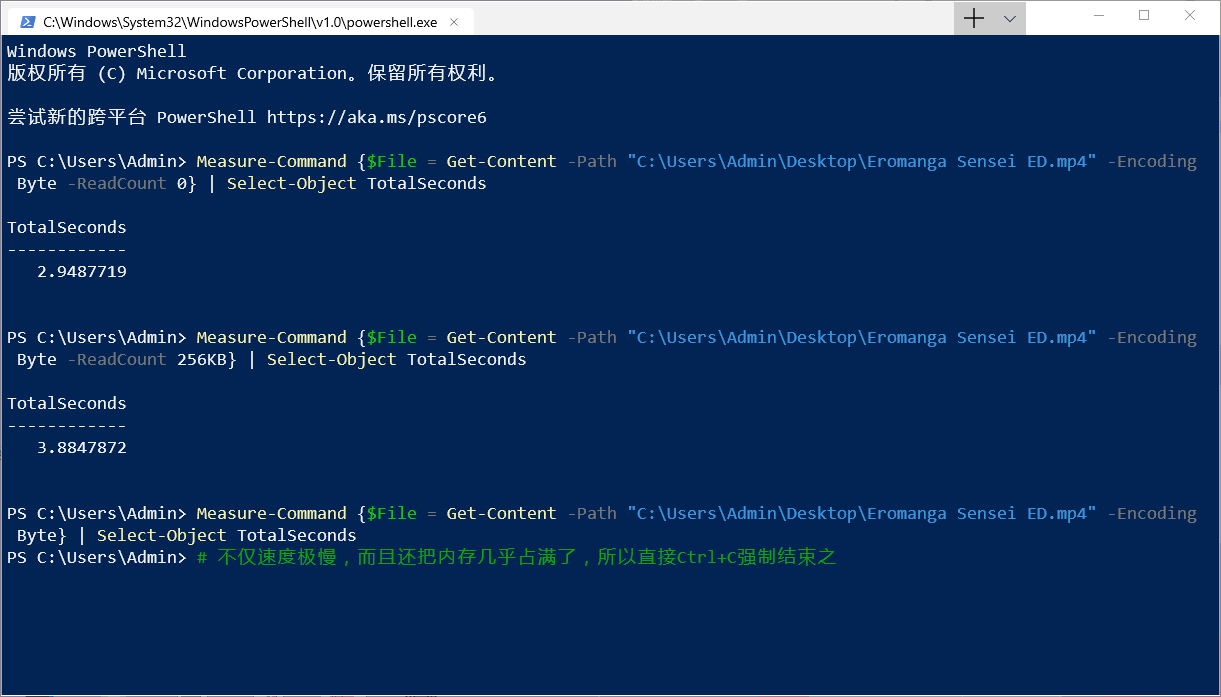
速度有所提升,但是折算下来的读取速度在 10MB/s 左右,这不是一块固态硬盘应有的读取速度。如果要进一步改进的话,难道又要手动折腾 .NET 对象了吗?!(°ー°〃)
设定 ReadCount 的方法是小透明在 Stack Overflow 上找到的,不过下面就有人给出了更简单直接的方法,也是几乎没有性能损耗的方法:使用 cmd 的 copy 命令∑(゚ω゚∪)
copy /b part1.bin+part2.bin+part3.bin merge.bin不过既然是用上了 cmd,就有必要考虑一下文件路径的问题……比如文件路径如果带有空格,就应该用引号包住,否则会被当成两个不同的参数。另外,使用相对路径容易产生错误,因此需要根据相对路径获取绝对路径。
PowerShell 的 cmdlet Resolve-Path 可以用来获取绝对路径,但是只能用于硬盘上已经存在的文件。获取不存在的文件的绝对路径就要使用 $ExecutionContext.SessionState.Path.GetUnresolvedProviderPathFromPSPath(String) 这一长串东西了。
把以上的操作组合起来,就是下面的函数:
# 合并文件
# [String[]]$Source: 所有要进行合并的源文件的路径
# [String]$Destination: 合并后的文件的保存路径
function Merge-File([String[]]$Source, [String]$Destination) {
# PowerShell中让某个变量等于一个数组,赋值的实际上是数组的引用,而不是复制了一份的数组,因此这里需要手动复制
$Source = $Source.Clone()
# 将源文件的路径转换为绝对路径,用引号包住
for ($i = 0; $i -lt $Source.Length; $i++) {
$Source[$i] = '"' + $ExecutionContext.SessionState.Path.GetUnresolvedProviderPathFromPSPath($Source[$i]) + '"'
}
# 将源文件路径的数组转换为cmd的copy命令接受的格式(各个文件路径之间使用+连接),合并文件
cmd /c copy /b /y ($Source -join '+') $ExecutionContext.SessionState.Path.GetUnresolvedProviderPathFromPSPath($Destination) | Out-Null
}如果线程开得太多(比如一口气开了 128 个),那就不能使用 copy 一次性合并所有文件了,原因是临时文件太多,组合起来的路径太长。根据微软官方的说明,cmd 中单条命令的长度不能超过 8191 个字符┓( ´∀` )┏
On computers running Microsoft Windows XP or later, the maximum length of the string that you can use at the command prompt is 8191 characters. On computers running Microsoft Windows 2000 or Windows NT 4.0, the maximum length of the string that you can use at the command prompt is 2047 characters.
In a batch file, the total length of the following command line after you expand the environment variables in the command line cannot contain more than either 2047 or 8191 characters (as appropriate to your operating system).
ExecutableFile.exe parameter1 parameter2 …
“多线程下载”的实现
和一开始说的一样,多线程下载的过程可以分为四个部分:获取大小,计算范围,建立线程,合并文件。除了“建立线程”之外的三个部分都非常简单,没有什么技术含量,很容易就可以实现~☆ミ(o*・ω・)ノ*
# 使用多线程下载文件
# [String]$Uri: 下载文件的地址
# [String]$OutFile: 保存文件的路径
# [Int32]$ThreadCount: 使用的线程数量
# [String]$UserAgent: 下载文件时使用的UA
function MultiThreadDownload-File([String]$Uri, [String]$OutFile, [Int32]$ThreadCount = 4, [String]$UserAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0') {
# 获取文件大小
[Int64]$Length = (Invoke-WebRequest $Uri -Method Head -UseBasicParsing).Headers.'Content-Length'
# 表示每个线程使用的临时文件路径和下载范围的三个数组,数组的下标就是对应的线程的编号
[Int64[]]$Start = @()
[Int64[]]$End = @()
[String[]]$Part = @()
# 计算下载范围,使用生成的GUID作为临时文件的名称
for ($i = 0; $i -lt $ThreadCount; $i++) {
$Start += $End[$i - 1] + [Int64](!!$i)
$End += [Math]::Round($Length / $ThreadCount * ($i + 1))
$Part += $ExecutionContext.SessionState.Path.GetUnresolvedProviderPathFromPSPath([GUID]::NewGuid().ToString('N') + '.bin')
}
# 建立线程开始下载
for ($i = 0; $i -lt $ThreadCount; $i++) {
...
}
# 等待所有线程下载完成
while (...) {
...
}
# 合并临时文件,然后删除
Merge-File -Source $Part -Destination $OutFile
foreach ($p in $Part) {Remove-Item $p}
}真正复杂的是“建立线程”这一部分(;-_-)关于在 PowerShell 中使用多线程的基本理论可以参考这里。
使用 cmdlet 实现多线程
使用多线程的简单方法是使用几个名称形如 *-Job 的 cmdlet,例如:
Measure-Command {
# 建立线程
# ScriptBlock指定了线程执行的PowerShell代码
# Start-Sleep可以让线程停止执行一段时间
Start-Job -ScriptBlock {Start-Sleep -Seconds 3} | Out-Null
Start-Job -ScriptBlock {Start-Sleep -Seconds 4} | Out-Null
Start-Job -ScriptBlock {Start-Sleep -Seconds 5} | Out-Null
# 用while循环将主线程“卡住”,只有在所有线程结束之后才继续执行
# 使用Measure-Command计算主线程被“卡住”的时间,也就是所有线程执行的时间
while (Get-Job -State Running) {
Start-Sleep -Milliseconds 20
}
} | Select-Object TotalSeconds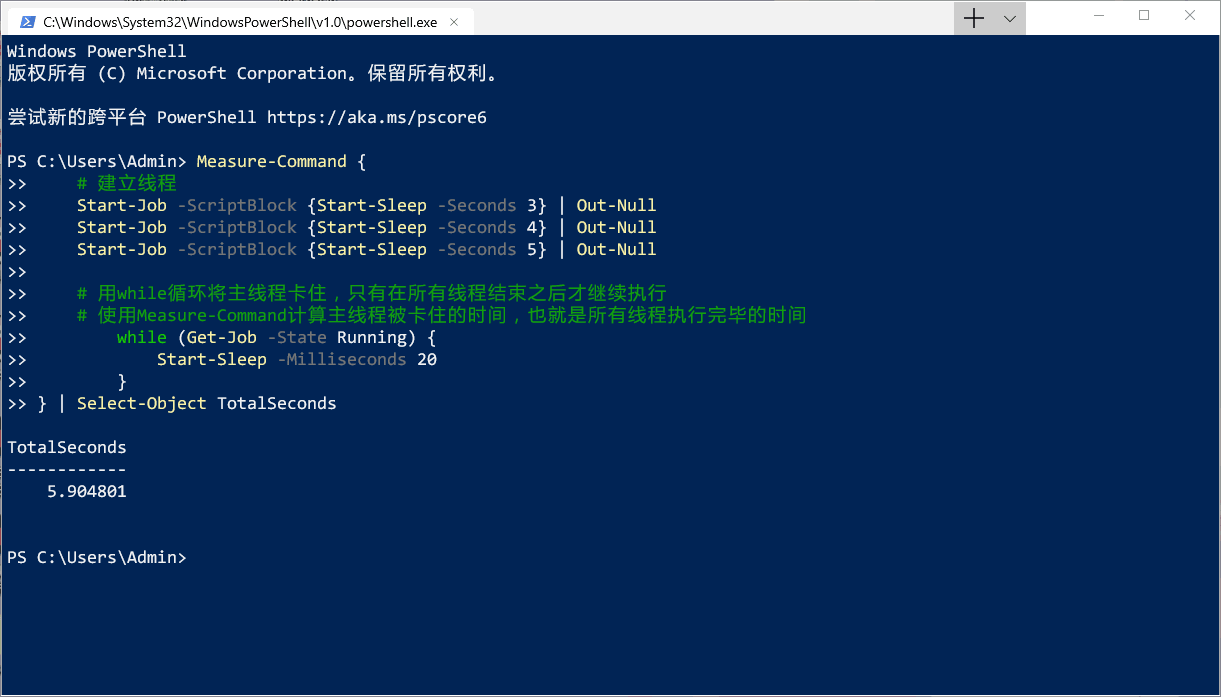
多线程确实起到了效果~这里的三个线程,如果顺序执行的话需要 12 秒,但是使用多线程的话就可以同时进行,耗时是所有线程执行时间的最大值,不过还要加上建立线程的时间。
但是小透明在实际使用的时候遇到了一个坑:上面的例子中 ScriptBlock 中的代码调用的是内置的 cmdlet,而实现分片下载调用的是在脚本中自定义的一个函数,然而直接在 Script 里调用自定义的函数的话就会……
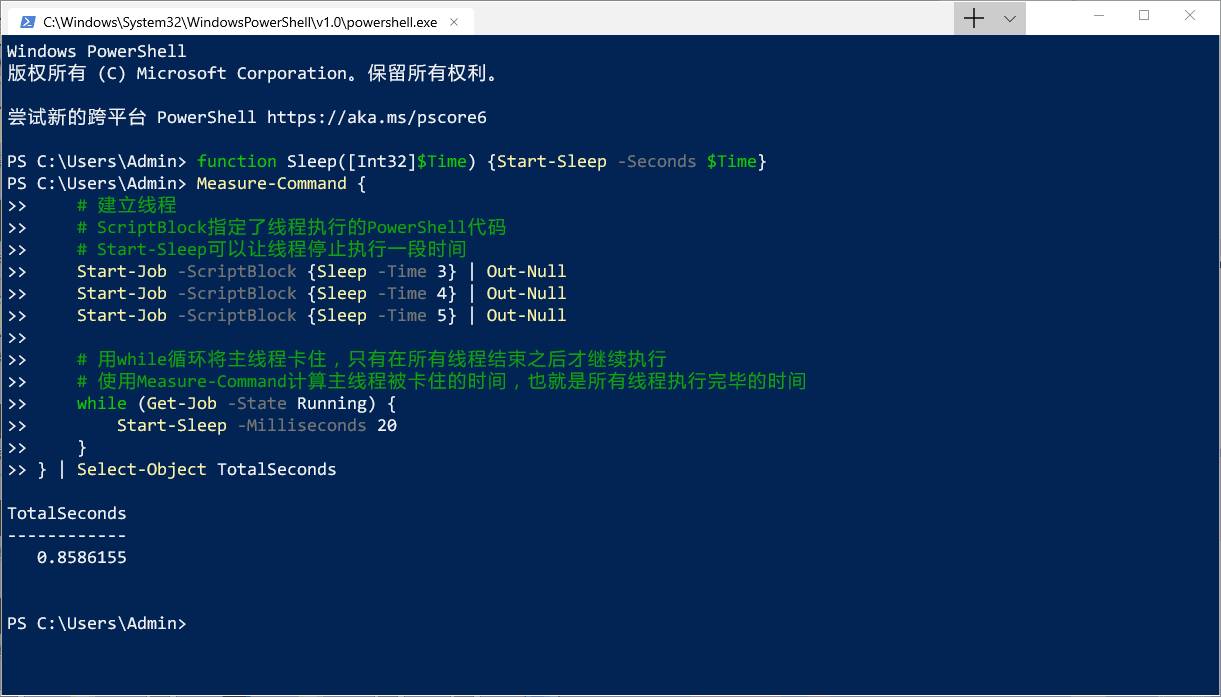
把 Start-Sleep 换成了相同效果的自定义函数 Sleep,结果完全没有执行啊喂!(ಡ_ಡ゙)
Sleep 这个自定义的函数只是在主线程(也就是当前打开的这个 PowerShell)中有定义,但在新建立的线程中是不存在的,直接将调用函数写进 ScriptBlock 的话,每个新线程就只能输出一次黑底红字无法将“Sleep”项识别为 cmdlet、函数、脚本文件或可运行程序的名称,然而主线程是看不到报错提示的ヘ(´ー`ヘ)
正确的做法是把函数本体通过函数变量 ${Function:<函数名称>} 传给线程,然后按照顺序在 ArgumentList 中指定参数,这样线程才能正常地调用函数( ・ㅂ・)و ̑̑
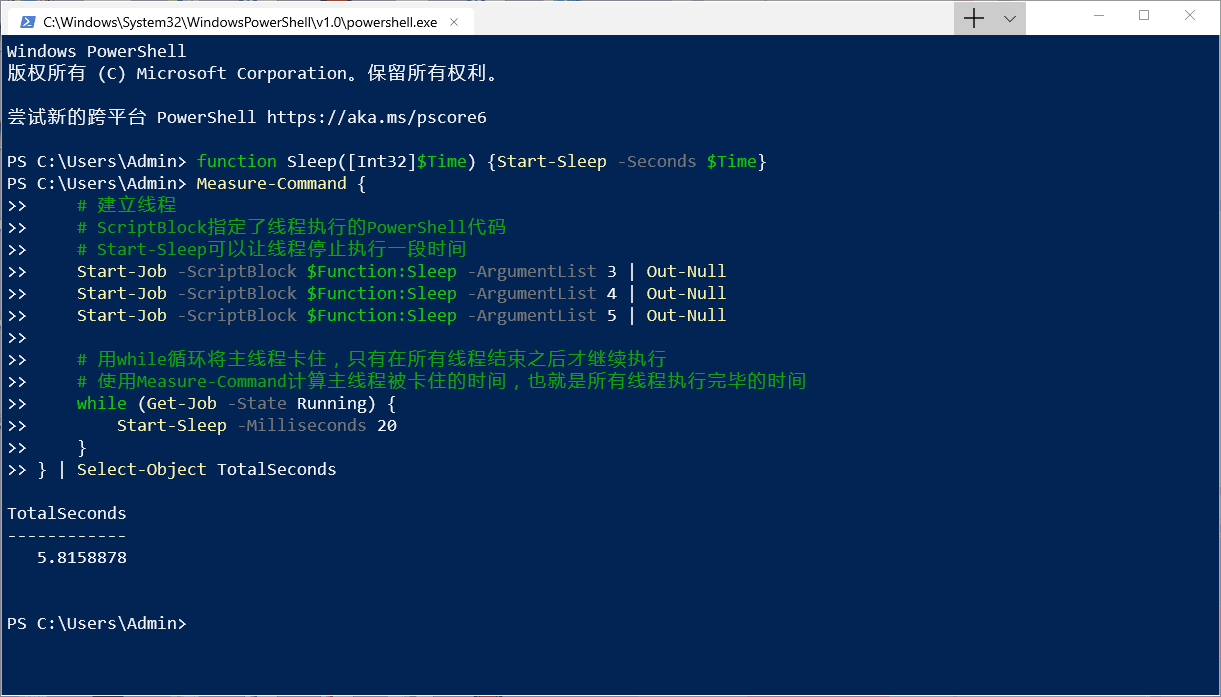
熟悉了建立线程的操作后,就可以开始编写相关的代码了(・∀・)つ另外,等待下载完成的时候主线程什么都不做也不好,可以使用 Write-Progress 为每个线程的下载进度显示一个进度条~
# 为每个线程计算完下载范围之后
# 建立下载线程
for ($i = 0; $i -lt $ThreadCount; $i++) {
Start-Job -ScriptBlock ${Function:PartiallyDownload-File} -ArgumentList $Uri,$Part[$i],$Start[$i],$End[$i],$UserAgent | Out-Null
}
[Double]$Progress = 0 # 暂时保存某个线程的下载进度百分比
[Int32]$Interval = 200 # 进度条的刷新间隔
while (Get-Job -State Running) {
Start-Sleep -Milliseconds $Interval
for ($i = 0; $i -lt $ThreadCount; $i++) {
# 如果线程还没有开始下载,即写入的临时文件还没有建立,则跳过显示进度条的操作
if (!(Test-Path $Part[$i])) {continue}
# 计算下载进度:获取临时文件的大小,除以下载范围的长度
$Progress = (Get-Item $Part[$i]).Length / ($End[$i] - $Start[$i] + 1) * 100
# 在进度条中显示线程编号、下载范围和下载进度
Write-Progress -Id $i -Activity ('Thread #{0} {1} - {2}' -f $i,$Start[$i],$End[$i]) -Status ('{0} / {1} {2:f2}%' -f (Get-Item $Part[$i]).Length,($End[$i] - $Start[$i] + 1),$Progress) -PercentComplete $Progress
}
}
# 下载结束后使用Completed参数隐藏进度条
for ($i = 0; $i -lt $ThreadCount; $i++) {
Write-Progress -Id $i -Activity ('Thread {0} - {1}' -f $Start[$i],$End[$i]) -Completed
}
# 销毁所有建立的线程
Remove-Job *
# 接下来执行“合并文件”的操作不使用 cmdlet 实现多线程
把上面的代码组合起来,已经足够可以实现多线程下载了d(゚∀゚d)
但是这个实现方案有一个缺点……Start-Job 并不是真正的多线程,只是另外开了一个 powershell.exe 的进程,结果就是下载时在任务管理器里可以看到一大堆 powershell.exe,就像 Chrome 和 Firefox 那样╮( •́ω•̀ )╭
使用多进程不仅不优雅,还会造成严重的性能损耗,每开一个 powershell.exe 就需要占用将近 30MB 的内存。虽然内存确实是拿来用的,不是给那些“○○管家”“○○卫士”的加速球清着玩的,但也不是这么随便浪费的(`ヘ´)ノ☆(#>_<)
真正的多线程需要使用 System.Management.Automation.PowerShell 这个类(文档甚至连机翻都没有了……),可以单独新建一个线程执行 PowerShell 脚本。这个类中可以用到的方法有这些:
Create()用于新建线程。AddCommand(String)用于为线程添加 PowerShell 代码。AddParameter(String, Object)用于添加参数。IsCompleted()用于检测线程是否执行完毕。Invoke()用于同步执行线程。(但是就没有多线程操作的意义了)BeginInvoke()用于异步执行线程,返回的System.IAsyncResult包含了这个线程的状态信息。EndInvoke(IAsyncResult)用于结束线程的执行,返回线程执行的结果。(然而这里每个线程的任务只是下载文件而已,没有输出,所以不需要接收结果)
添加代码和参数的两个方法返回的是 PowerShell 线程本体,有点链式调用的风格~把上面的例子用这里的方法改写一下:
function Sleep([Int32]$Time) {Start-Sleep -Seconds $Time}
Measure-Command {
# 建立线程
[Management.Automation.PowerShell[]]$Job = @()
[Object[]]$Handle = @()
for ($i = 0; $i -lt 3; $i++) {
$Job += [PowerShell]::Create().AddScript(${Function:Sleep}).AddParameter('Time', $i + 3)
$Handle += $Job[$i].BeginInvoke()
}
# 在循环中检查所有线程是否已执行完成
[Boolean]$Complete = $false
while (!$Complete) {
Start-Sleep -Milliseconds 20
$Complete = $true
for ($i = 0; $i -lt 3; $i++) {
if (!$Handle[$i].IsCompleted) {
$Complete = $false
break
}
}
}
} | Select-Object TotalSeconds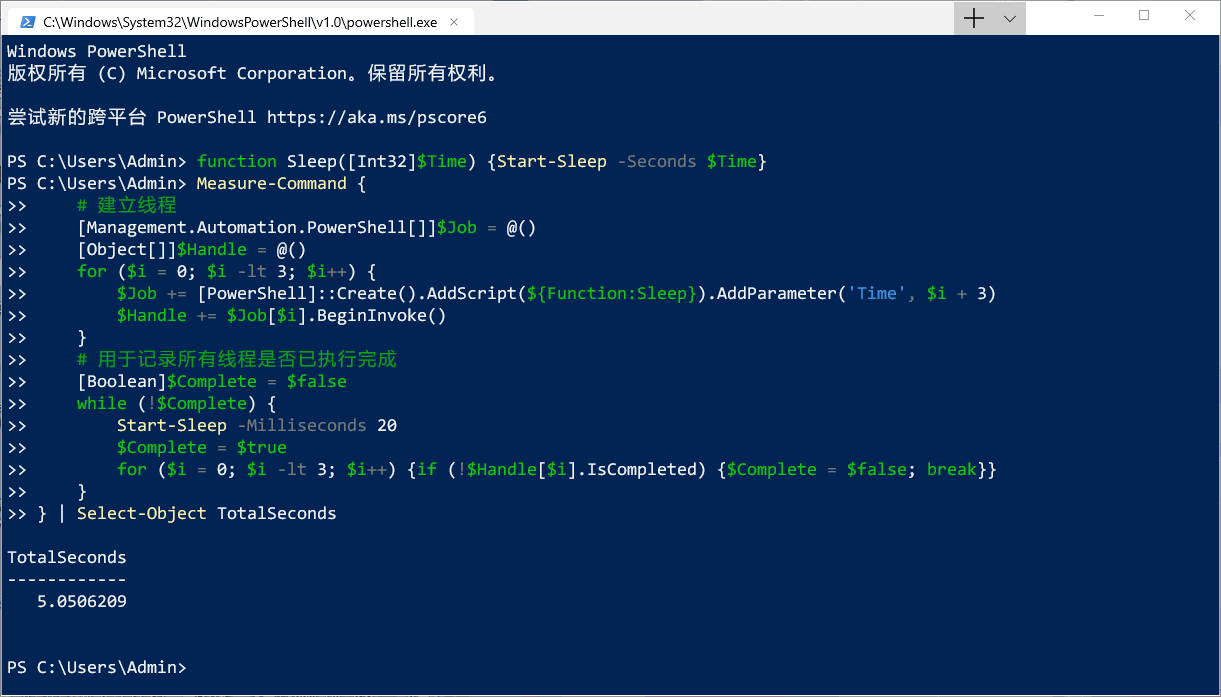
从执行时间可以看出,这种方法在建立线程消耗的时间上比使用 cmdlet 更少:后者需要 0.8~0.9 秒来建立线程,但是使用这种方法建立线程的耗时不到 0.1 秒,而且也不会给每个线程开一个 powershell.exe 占用大量内存(一上来就占用 30MB),线程的内存按需取用,而且是算在主进程名下的(´゚ω゚`)
线程开多了 CPU 占用率会大幅增加,不过这个是可以接受的。如果有特别需求的话,也可以考虑使用线程池,限定同时只能执行若干个进程。
function Sleep([Int32]$Time) {
Start-Sleep -Milliseconds $Time
Write-Host ('Sleep Time: ' + $Time)
}
Measure-Command {
# 建立同时最多执行1~4个线程的线程池
$ThreadPool = [RunspaceFactory]::CreateRunspacePool(1, 4, $Host)
$ThreadPool.Open()
# 建立线程
[Management.Automation.PowerShell[]]$Job = @()
[Object[]]$Handle = @()
for ($i = 0; $i -lt 16; $i++) {
$Job += [PowerShell]::Create().AddScript(${Function:Sleep}).AddParameter('Time', (Get-Random -Minimum 1500 -Maximum 2500))
$Job[$i].RunspacePool = $ThreadPool
$Handle += $Job[$i].BeginInvoke()
}
# 在循环中检查所有线程是否已执行完成
[Boolean]$Complete = $false
while (!$Complete) {
Start-Sleep -Milliseconds 20
# 每次检查时,仅当所有线程已完成,$Complete才可能为true
# 检查到任何一个未完成的线程都会使这个变量为false
$Complete = $true
for ($i = 0; $i -lt 16; $i++) {
# 跳过对已完成线程的检查
if ($Handle[$i] -eq $null) { continue }
# 如果线程已完成,则返回输出,销毁线程,从线程池中移出
if ($Handle[$i].IsCompleted) {
$Job[$i].EndInvoke($Handle[$i])
$Job[$i].Dispose()
$Handle[$i] = $null
} else {
$Complete = $false
}
}
}
} | Select-Object TotalSeconds改进后的操作线程的代码:
# 为每个线程计算完下载范围之后
# 保存线程信息的数组
[Management.Automation.PowerShell[]]$Job = @()
[Object[]]$Handle = @()
# 建立下载线程
for ($i = 0; $i -lt $ThreadCount; $i++) {
$Job += [PowerShell]::Create().AddScript(${Function:PartiallyDownload-File}).AddParameter('Uri', $Uri).AddParameter('OutFile', $Part[$i]).AddParameter('Start', $Start[$i]).AddParameter('End', $End[$i]).AddParameter('UserAgent', $UserAgent)
$Handle += $Job[$i].BeginInvoke()
}
[Double]$Progress = 0 # 暂时保存某个线程的下载进度百分比
[Int32]$Interval = 200 # 进度条的刷新间隔
[Boolean]$Complete = $false # 表示所有线程的完成情况
while (!$Complete) {
Start-Sleep -Milliseconds $Interval
# 在循环中检查所有线程是否已执行完成
$Complete = $true
for ($i = 0; $i -lt $ThreadCount; $i++) {
if (!$Handle[$i].IsCompleted) {
$Complete = $false
break
}
}
for ($i = 0; $i -lt $ThreadCount; $i++) {
# 如果线程还没有开始下载,即写入的临时文件还没有建立,则跳过显示进度条的操作
if (!(Test-Path $Part[$i])) {continue}
# 计算下载进度:获取临时文件的大小,除以下载范围的长度
$Progress = (Get-Item $Part[$i]).Length / ($End[$i] - $Start[$i] + 1) * 100
# 在进度条中显示线程编号、下载范围和下载进度
Write-Progress -Id $i -Activity ('Thread #{0} {1} - {2}' -f $i,$Start[$i],$End[$i]) -Status ('{0} / {1} {2:f2}%' -f (Get-Item $Part[$i]).Length,($End[$i] - $Start[$i] + 1),$Progress) -PercentComplete $Progress
}
}
for ($i = 0; $i -lt $ThreadCount; $i++) {
# 下载结束后使用Completed参数隐藏进度条
Write-Progress -Id $i -Activity ('Thread {0} - {1}' -f $Start[$i],$End[$i]) -Completed
# 结束和销毁线程
$Job[$i].EndInvoke($Handle[$i])
$Job[$i].Runspace.Close()
$Job[$i].Dispose()
}
# 接下来执行“合并文件”的操作其实还可以继续改进的~比如每个线程可以在下载完成后立即销毁并隐藏对应的进度条,不用等到下载结束后统一销毁。
其他的一些优化(?)
根据 Stack Overflow 上的某个问题,直接使用 WebRequest 还是太慢。下面的回答中给出了两个优化的方法,不过小透明并没有测试过实际效果……也许真的有用?
# 将同时使用的网络连接数量设为最大值,默认为2
[Net.ServicePointManager]::DefaultConnectionLimit = [Int32]::MaxValue
...
# 禁用对网络代理的搜索
$Request = [Net.WebRequest]::Create($Uri)
$Request.Proxy = $null完整的代码可以在这里下载~( ◞´•௰•`)◞
多线程下载函数的使用方法:
# 使用多线程下载文件
# [String]$Uri: 下载文件的地址
# [String]$OutFile: 保存文件的路径
# [Int32]$ThreadCount: 使用的线程数量(可选,默认为4)
# [Int32]$MinSliceSize: 分配给每个线程下载的数据量的下限,若线程过多则根据此参数强制减少线程数(可选,默认为256KB)
# [String]$UserAgent: 下载文件时使用的UA(可选,有默认值)
MultiThreadDownload-File -Uri '...' -OutFile '...' -MinSliceSize 256KB -ThreadCount 4 -UserAgent '...'本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2019/06/05/powershell-multithread-download/