
封面图:Pixiv ID: 75886262 「お誕生日おめでとうあかり!Happy Birthday!」 by Kyouzama アリンスター
不知道是不是被“精准营销”了,总之小透明最近在很多网站上都看到了各种“Python 入门教程”(`へ´*)ノ
一想到 Python 入门,小透明就记得诸如 C$DN 之类的网站上经常会使用制作各种爬虫作为 Python 入门的案例是。一提到 Python 的入门级爬虫,似乎大部分教程都在爬各种妹子图网站。如果这些网站的站长们发现自己的网站除了吸引肥宅以外居然还能成为编程入门教具之一,不知道会有什么感想呢?(´゚ω゚`)
迷之声:“给我也整一个!”
由于用 Python 写的妹子图爬虫实在是太多了,复读这些教程也没什么意思,所以小透明还是打算使用熟悉的 PowerShell 来编写爬虫~当然也就不需要装各种包配置各种环境(右键就可以直接运行,Windows 内置了 PowerShell 的运行环境,甚至还内置了一个 IDE),而且诸君看了以下的教程后,也许能举一反三,制作适用于其它(爬取难度较低的)网站的爬虫也说不定?
当然,制作网站爬虫,基本的网络编程知识还是需要有的~
这里要爬取的是 https://www.mzitu.com/ 这个网站。虽然它显然不是唯一的妹子图网站,不过这个网站出现在了大部分爬虫教程中(站长真可怜 233),而且访问速度也很快,所以就用它作为例子(ᴗ•̀ᴗ-)✧ 小透明找到的另外一个妹子图网站是 https://meizitu.com/,但是似乎是需要翻墙才能访问……有条件的话,也可以开着梯子爬一下试试看?
使用 ParsedHTML 解析网页数据
PowerShell 访问网页用的是 Invoke-WebRequest 这个 cmdlet,比如要访问妹子图网站的主页:
$Response = Invoke-WebRequest 'https://www.mzitu.com/page/1/'得到的 $Response 就是包含了网页数据的对象:
StatusCode : 200
StatusDescription : OK
Content : <!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>妹子图 - 性感美女图片每日更新</title>
<meta name="keywords" content="妹子图,妹子,美女图片,性感美女,美女写真" />
<meta name=...
RawContent : HTTP/1.1 200 OK
Connection: keep-alive
X-NWS-UUID-VERIFY: ce2a0876df4584dcf4baa32cd89c7195
X-NWS-LOG-UUID: 56e2625d-3abc-4866-a94f-6b0e4c316bf0
X-Cache-Lookup: Hit From Disktank3,Hit From Inner Cl...
Forms : {}
Headers : {[Connection, keep-alive], [X-NWS-UUID-VERIFY, ce2a0876df4584dcf4baa32cd89c7195], [X-NWS-LOG-UUID,
56e2625d-3abc-4866-a94f-6b0e4c316bf0], [X-Cache-Lookup, Hit From Disktank3,Hit From Inner Cluster,H
it From Upstream]...}
Images : {@{innerHTML=; innerText=; outerHTML=<IMG class=lazy alt="有胸有腿有翘臀 妩媚尤物芝芝Booty黑丝一线裆让你大饱眼福" src="http
s://i.meizitu.net/pfiles/img/lazy.png" width=236 height=354 data-original="https://i.meizitu.net/th
umbs/2019/07/189007_10b27_236.jpg">; outerText=; tagName=IMG; class=lazy; alt=有胸有腿有翘臀 妩媚尤物芝芝Booty黑丝
一线裆让你大饱眼福; src=https://i.meizitu.net/pfiles/img/lazy.png; width=236; height=354; data-original=http
s://i.meizitu.net/thumbs/2019/07/189007_10b27_236.jpg}...}
InputFields : {@{innerHTML=; innerText=; outerHTML=<INPUT class=search-input name=s placeholder="搜一搜,看一看">; outer
Text=; tagName=INPUT; class=search-input; name=s; placeholder=搜一搜,看一看}}
Links : {@{innerHTML=妹子图; innerText=妹子图; outerHTML=<A href="https://www.mzitu.com/">妹子图</A>; outerText=妹子图;
tagName=A; href=https://www.mzitu.com/}, @{innerHTML=首页; innerText=首页; outerHTML=<A title=首页 href=
"https://www.mzitu.com/" aria-current="page">首页</A>; outerText=首页; tagName=A; title=首页; href=https:
//www.mzitu.com/; aria-current=page}...}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 22250显而易见,$Response.Content 就是网页的所有源代码。小透明很久以前用 PowerShell 写过一个从 https://ffmpeg.zeranoe.com/builds/ 自动下载更新电脑上的 FFmpeg 的脚本,需要从网页上获取 https://ffmpeg.zeranoe.com/builds/win64/shared/ffmpeg-20190729-43891ea-win64-shared.zip 这样的下载链接。由于当时的姿势水平实在是不怎么高,小透明当时使用的方法就是直接从网页源代码中使用正则表达式去搜索……( ε:)
能直接查找下载链接是因为下载链接的格式相当固定(会改变的元素仅有是八位数字的日期和七位十六进制数字的 Git 提交版本号),但是实在是太不优雅了,而且通用性也不强⊂彡☆))∀`)
更优雅的查找方式是通过 $Response.ParsedHTML.documentElement 这个使用了 IE 浏览器对网页源代码进行解析的产物(由此可见为什么 IE 浏览器已经严重过时但是仍然没有被 Windows 砍掉,它早就成为了被很多程序在 Windows 系统中使用的访问网络的“基础设施”),有点像用浏览器打开某网页后 F12 然后找到控制台输入 document 得到的东西,当然也就可以像 JavaScript 一样对 DOM 节点进行很多基本的操作:
- 查找元素:
getElementById、getElementsByClassName、getElementsByTagName(不包括使用 CSS 进行选择的querySelector和querySelectorAll) - 查找父子兄弟节点:
previousSibling、nextSibling、parentElement、children - 获取元素内的数据:
innerText、innerHTML - 获取元素的属性:
getAttribute
不过这里有一个坑:$Response.ParsedHTML.documentElement 和 $Response.ParsedHTML非常容易混淆,这两个对象的类型是不同的,能进行的操作也不同。前者可以使用以上的所有操作但是**不能使用 getElementById,后者只能使用以上操作中的 getElementById 和 getElementsByTagName**……不知道为什么会弄出这种区别(っ’-‘)╮
另外“查找元素”和“查找父子兄弟节点”得到的对象和 $Response.ParsedHTML.documentElement 是相同的类型。
PowerShell 6 中
ParsedHTML被微软大刀部砍掉了,不过 Windows 10 内置的是 PowerShell 5.1,因此不受影响~
分析网页,获取套图信息
妹子图网站的主页上每一页有若干组套图的链接,对照着网页源代码就可以找到和套图相关的部分(っ’ω’)っ
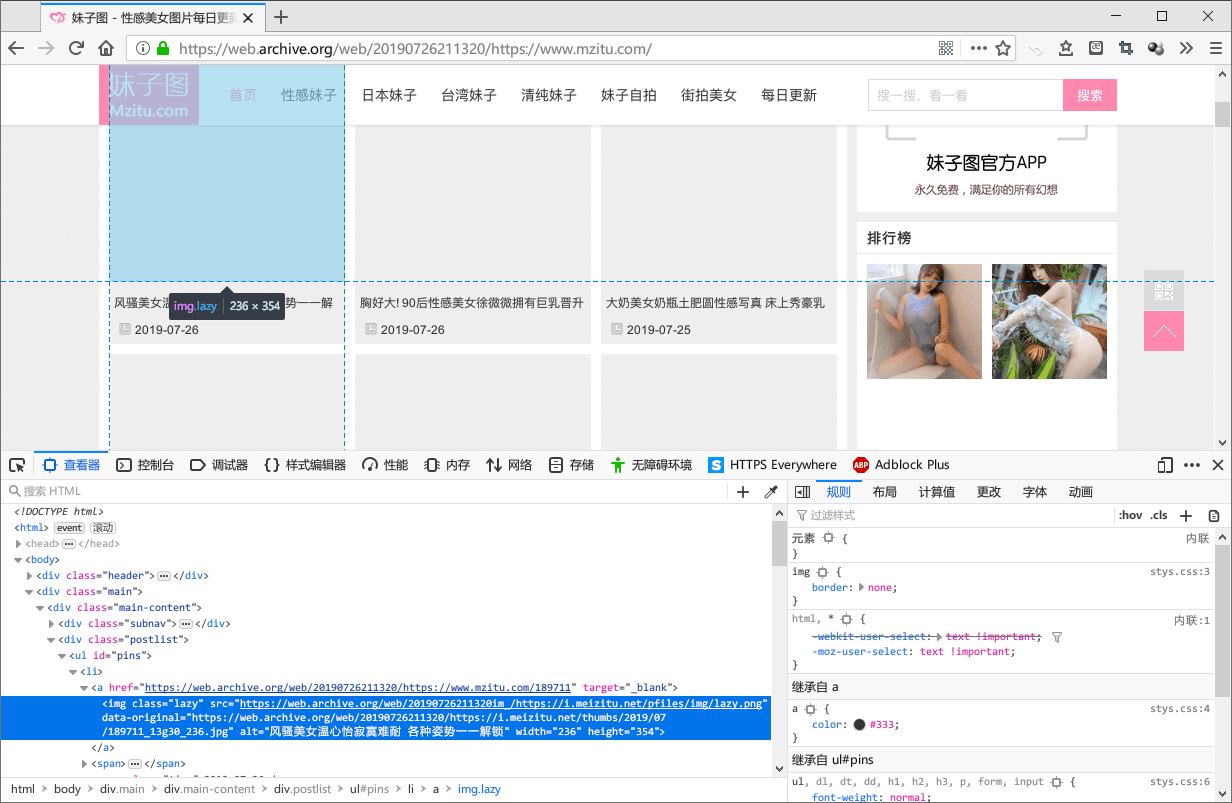
<ul id="pins">
<li>
<a href="https://www.mzitu.com/189007" target="_blank">
<img class='lazy' src='https://i.meizitu.net/pfiles/img/lazy.png' data-original='https://i.meizitu.net/thumbs/2019/07/189007_10b27_236.jpg' alt='有胸有腿有翘臀 妩媚尤物芝芝Booty黑丝一线裆让你大饱眼福' width='236' height='354' />
</a>
<span><a href="https://www.mzitu.com/189007" target="_blank">有胸有腿有翘臀 妩媚尤物芝芝Booty黑丝一线裆让你大饱眼福</a></span>
<span class="time">2019-07-29</span>
</li>
<li>
<a href="https://www.mzitu.com/193773" target="_blank">
<img class='lazy' src='https://i.meizitu.net/pfiles/img/lazy.png' data-original='https://i.meizitu.net/thumbs/2019/07/193773_07b27_236.jpg' alt='温柔体贴的小女仆 甜美嫩模toro羽住高清美照梦幻动人' width='236' height='354' />
</a>
<span><a href="https://www.mzitu.com/193773" target="_blank">温柔体贴的小女仆 甜美嫩模toro羽住高清美照梦幻动人</a></span>
<span class="time">2019-07-29</span>
</li>
<li>
……
</li>
</ul>如果要获取套图的链接和标题,也就要获取到 <a href="(套图链接)" target="_blank">(套图标题)</a> 这样的节点。获取到第一页的所有套图信息的代码如下:
$Response = Invoke-WebRequest 'https://www.mzitu.com/page/1/'
# 获取document
# $Response.ParsedHTML
# 获取<ul id="pins">
# $Response.ParsedHTML.getElementById('pins')
# 每一组套图对应<ul id="pins">中的每一个<li>
# $Response.ParsedHTML.getElementById('pins').children
# $Response.ParsedHTML.getElementById('pins').getElementsByTagName('li')
# 显然选择器的写法是不唯一的~
foreach ($li in $Response.ParsedHTML.getElementById('pins').children) {
# 获取套图链接的<a>外面的<span>
# $li.children[1]
# $li.firstChild.nextSibling
# 获取套图链接的<a>本身
# $li.children[1].firstChild
# $li.children[1].children[0]
# 从<a>获取套图的标题和链接
Write-Host ('URL: ' + $li.children[1].firstChild.href)
Write-Host ('Title: ' + $li.children[1].firstChild.innerText)
}那第二页、第三页……的套图呢?第一页的网址 https://www.mzitu.com/page/1/ 里面的这个 1,不就是页数嘛!
当时妹子图网站的页数是 226,写个循环就可以全部提取了੭ ᐕ)੭*⁾⁾ 不过这次要把所有套图的信息以对象的形式,保存到 $Articles 这个数组中:
$Articles = @()
for ($i = 1; $i -le 226; $i++) {
$SitePageURL = ('https://www.mzitu.com/page/' + $i + '/')
$SitePage = Invoke-WebRequest $SitePageURL
foreach ($ArticleEntry in $SitePage.ParsedHTML.getElementById('pins').children) {
$Articles += @{
'URL' = $ArticleEntry.firstChild.href + '/'
'Title' = $ArticleEntry.firstChild.nextSibling.firstChild.innerText
}
}
}还可以把套图的信息以 JSON 格式保存到文件中,之后下载时可以直接读取,而不需要重新爬取一遍:
# 保存
$Articles | ConvertTo-Json | Out-File 'D:\mzitu\mzitu.json'
# 读取
$Articles = Get-Content 'D:\mzitu\mzitu.json' | ConvertFrom-Json也可以从这里下载小透明已经爬取完了的套图信息~一共有 5423 条_(:△」∠)_
为了方便使用 PowerShell 直接读取,这个文件是使用 UTF-16 LE 编码保存的,因此直接用浏览器打开的话看到的可能是乱码。
自动下载妹子图
打开某一组套图的第一页,用同样的方法分析网页源代码,就可以得到每张图片的链接,以及这组套图的图片总数。
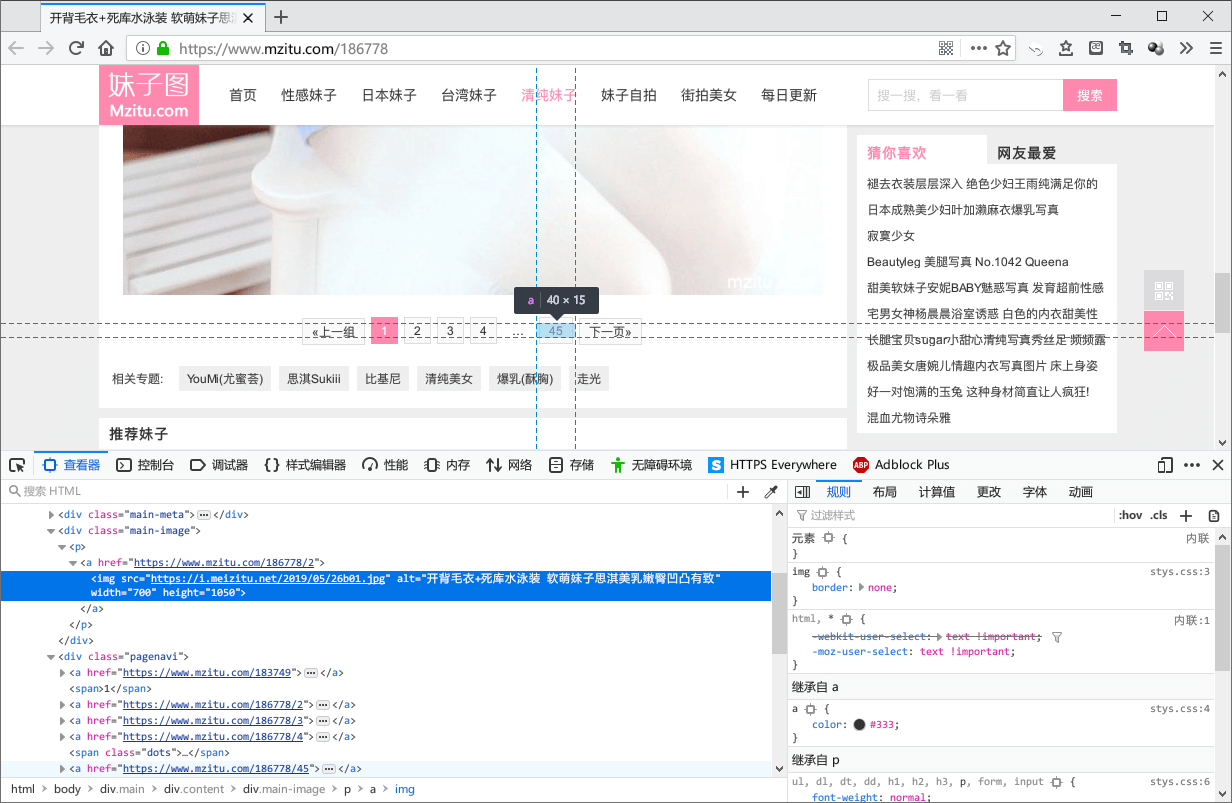
图片的链接在 <div class="main-image"> 里面的 <img> 中,总页数可以从最后一个跳转页面的按钮获取,也就是 <div class="pagenavi"> 的最后一个 <a>,写一个循环就可以把这组套图的所有图片下载下来~
# 读取之前获取的所有套图的信息
$Articles = Get-Content 'D:\mzitu\mzitu.json' | ConvertFrom-Json
for ($i = 0; $i -lt $Articles.Length; $i++) {
Write-Host ($Articles[$i].Title + ' ' + $Articles[$i].URL) -NoNewline
$ArticlePage = Invoke-WebRequest $Articles[$i].URL
# 获取每组套图的图片总数
# lastChild指向<div class="pagenavi">的最后一个空文本节点
# lastChild.previousSibling指向“下一页”的按钮
# lastChild.previousSibling.previousSibling指向的就是“下一页”的前一个,也就是可以跳转到最后一页的按钮
# 这个按钮里面的数字就是图片总数,用innerText获取
[Int32]$ArticlePageCount = $ArticlePage.ParsedHTML.documentElement.getElementsByClassName('pagenavi')[0].lastChild.previousSibling.previousSibling.innerText
# 根据套图名称建立文件夹
# 将函数的执行结果赋值给$null,可以隐藏掉新建文件夹时输出的提示文本,隐藏的方法也不唯一
$null = [IO.Directory]::CreateDirectory('D:\mzitu\' + $Articles[$i].Title)
# 使用类型转换:[void][IO.Directory]::CreateDirectory('D:\mzitu\' + $Articles[$i].Title)
# 使用管道接收输出:[IO.Directory]::CreateDirectory('D:\mzitu\' + $Articles[$i].Title) | Out-Null
# 循环下载所有图片
for ($j = 1; $j -le $ArticlePageCount; $j++) {
# 根据规律构造网页URL
# 例如 https://www.mzitu.com/189711/2 表示的就是这一组套图的第二张图
$ImagePageURL = $Articles[$i].URL + $j
$ImagePage = Invoke-WebRequest $ImagePageURL
# 获取图片的URL,构造保存路径
$ImageURL = $ImagePage.ParsedHTML.documentElement.getElementsByClassName('main-image')[0].getElementsByTagName('img')[0].src
$ImagePath = 'D:\mzitu\' + $Articles[$i].Title + '\' + [IO.Path]::GetFileName($ImageURL)
Write-Host $ImageURL -NoNewline
# 下载图片,保存到对应路径中
# 妹子图网站似乎有防盗链,在网页上可以正常加载图片,但是直接打开图片的URL会遇到403错误
# 在请求头中加上妹子图网站的链接就可以回避这一限制~
# 由于下载的是文件,不需要进行网页解析,所以可以加上-UseBasicParsing这个参数禁用解析,提高一点点速度
Invoke-WebRequest -Uri $ImageURL -Headers @{'Referer' = 'https://www.mzitu.com'} -OutFile $ImagePath -UseBasicParsing -UserAgent 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'
}
}只要运行了这段脚本,就可以源源不断地下载妹子图了~(⑉・̆-・̆⑉)
脚本优化
自动重连
如果因为网络问题导致页面加载失败的话,那么某一张妹子图的下载就会因为出错被直接跳过,这样的程序显然是缺少健壮性(?)的,因此就需要在页面加载失败时自动重新加载。把加载页面的代码放到 try {...} catch {...} 语句中就可以实现:
# 用一个变量标记是否加载成功
$Success = $false
# 除非加载成功一次,否则一直加载
while (!$Success) {
try {
# 设定十秒的连接时间限制,超时的话也会按加载失败处理
Invoke-WebRequest '...' -TimeoutSec 10
# Invoke-WebRequest的加载成功就会继续执行try部分的代码,并在控制台上输出绿色的Success
$Success = $true
Write-Host 'Success' -BackgroundColor DarkGreen -ForegroundColor White -NoNewLine
} catch {
# 加载失败就会跳转到catch部分,并在控制台上输出红色的Fail
$Success = $false
Write-Host 'Fail' -BackgroundColor DarkRed -ForegroundColor White -NoNewline
}
Write-Host ' ' -NoNewline
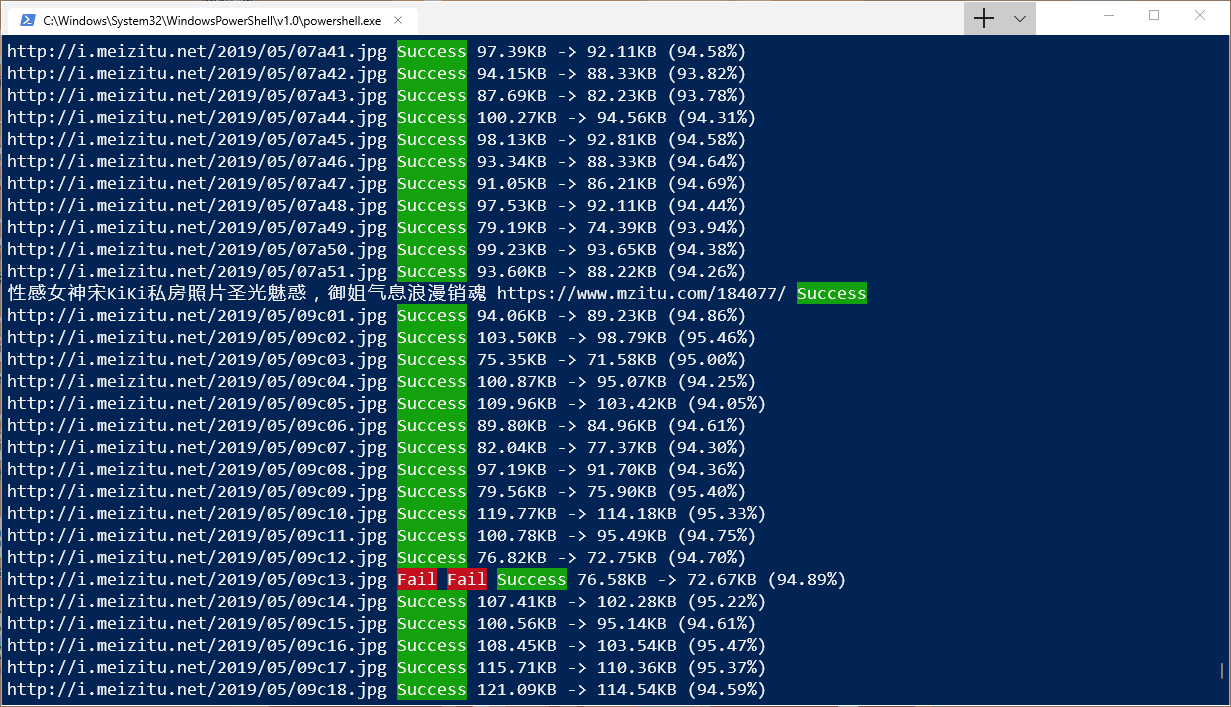
}如图所示,每次加载网页都会在控制台上输出一次加载结果,自动重连,一直到加载成功为止~
截图中还输出了文件大小和百分比之类的信息,是小透明自己添加的使用 jpegtran 对图片进行优化的效果。通过对图像数据进行重新排列,这个工具可以在不影响 JPEG 图片质量的情况下把图片变成渐进式,而且还能减少 5~7% 的文件大小٩( ‘ω’ )و
断点续爬
妹子图网站一共有五千多张套图,一次性爬取完成显然是不可能的,因此也有必要实现断点续爬的功能~
实现的原理也不难,把爬取的进度保存到一个文件中,每次运行脚本的时候读取一下就可以了,还可以跳过已经下载过的图片,避免重复下载。
$Articles = Get-Content 'D:\mzitu\mzitu.json' | ConvertFrom-Json
# 读取爬取进度
# 文件的内容是从0开始的一个数,表示目前爬取到了第几份套图
[Int32]$Start = Get-Content 'D:\mzitu\progress.txt'
# 循环也是从$Start开始的
for ($i = $Start; $i -lt $Articles.Length; $i++) {
# 将当前的爬取进度保存到文件中
$i > 'D:\mzitu\progress.txt'
# 获取套图的图片数量……
for ($j = 1; $j -le $ArticlePageCount; $j++) {
# 获取每张图片的URL并构造保存路径……
# 如果图片已经存在,就直接下载下一张图片,而不是重复下载
if ([IO.File]::Exists($ImagePath)) { continue }
# 根据URL下载图片……
}
}最后来一张爬取结果,一晚上爬了三百多份套图,一共一万多张图……|ω•`)
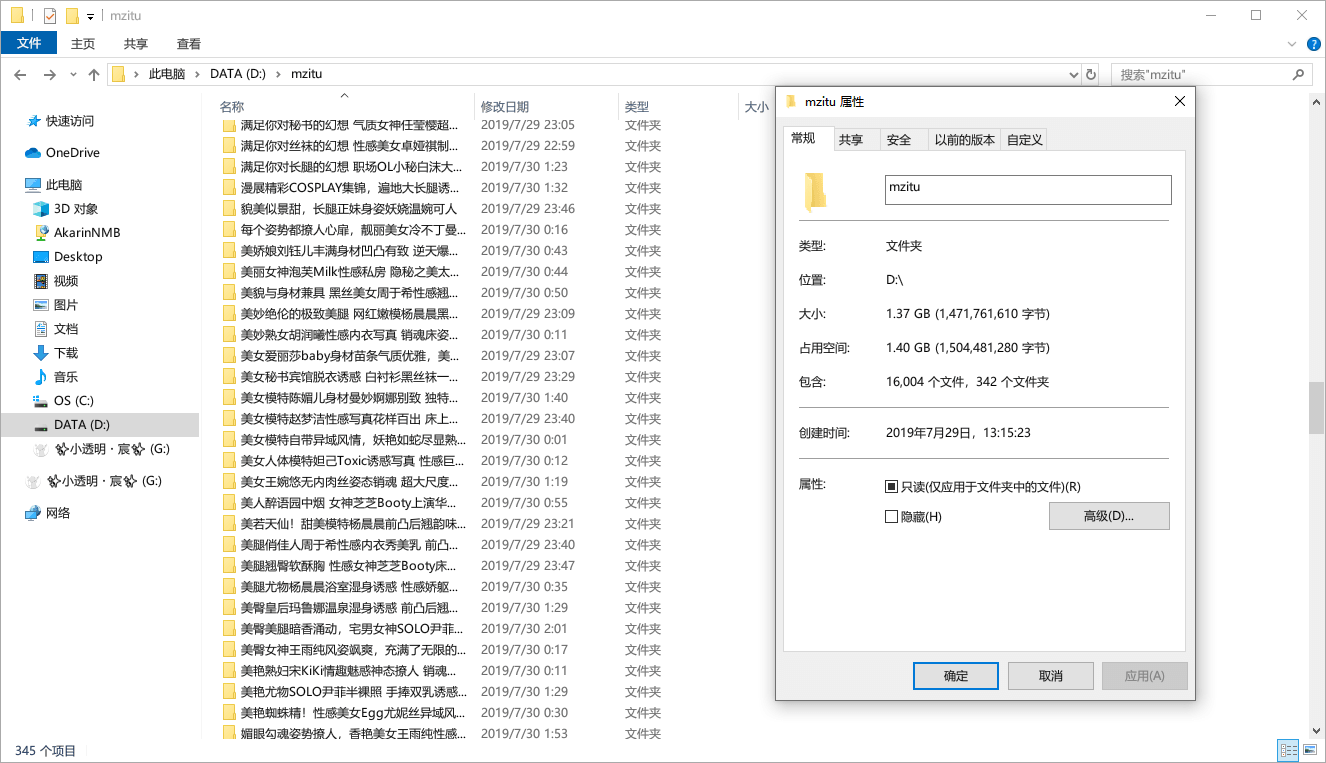
(然后被服务器关进小黑屋了,打开这个网站的所有图片都是 403,所以运行爬虫还得用代理啊喂!)
那么……妹子图呢?( ・᷄ὢ・᷅ )

这种妹子图有什么好看的,还是纸片人更可爱!σ*ゝω・)
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2019/07/30/powershell-mzitu-crawler/