
问题的背景
出于某些需求,我最近使用 Python 的 Selenium 模块,配合自动控制 Firefox 浏览器的 Geckodriver,编写和部署了一个自动完成某网站登录界面上的滑动验证码的服务。虽然这些验证码的宣传词上少不了“大数据”、“人工智能”、“高效拦截机器行为”之类的关键词,但是从现在在网上可以轻易搜索到的至少 114514 篇“○○滑动验证码破解”的文章来看,只要解决“寻找验证码缺口”和“拟合轨迹”这两个问题(当然,需要一些简单的图像处理和数学方面的知识),绝大多数的滑动验证码还是不堪一击的。
本来想在这里放上我编写的那个服务自动完成验证码的录屏,但是由于那里的验证码背景图可以暴露被我模拟登录的网站的信息,所以还是算了。作为替代,这里就放一张我当时写的几个拟合滑动轨迹的多项式函数图像吧 (*°∀°)=3
那个服务正常运行了大半个月,累计差不多模拟完成了一两百次滑动验证码,但是今天这个服务突然就无法正常使用了,到底是怎么回事呢?
基本的检测和伪装原理
根据大量的控制变量法和排除法分析,确定是由于 Selenium 控制的浏览器中存在的 navigator.webdriver 属性被检测到导致无法完成滑动验证码。这是个检查自动操作从而进行反爬的好方法,在正常的浏览器中这个属性的值为 undefined(在较新的浏览器里则为 false),如果浏览器被 Selenium 之类的工具自动控制的话则为 true。为了让服务可以继续运行,就有必要对它进行伪装了。
首先上一段最简单的代码,在配置好 Selenium 和 Geckodriver 之后就可以调用 Firefox 打开 https://bot.sannysoft.com/,这是一个可以展示浏览器属性,同时标出哪些属性可能会被检查为自动控制的浏览器的网站。
import time
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('https://bot.sannysoft.com/')
# driver.execute_script('delete navigator.__proto__.webdriver')
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
driver.quit()根据 MDN 上的介绍,navigator.webdriver 是个只读属性,所以不能通过覆盖值的方式来伪装。但是如果你稍微提高了一点姿势水平,就会知道可以通过重写这个属性的 getter 来把它覆盖掉。
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});虽然确实可以覆盖,但是这个伪装行为本身还是可以被检查出来。只要执行上面的代码添加了 getter,执行 navigator.hasOwnProperty('webdriver') 就会返回 true,未执行则不返回。
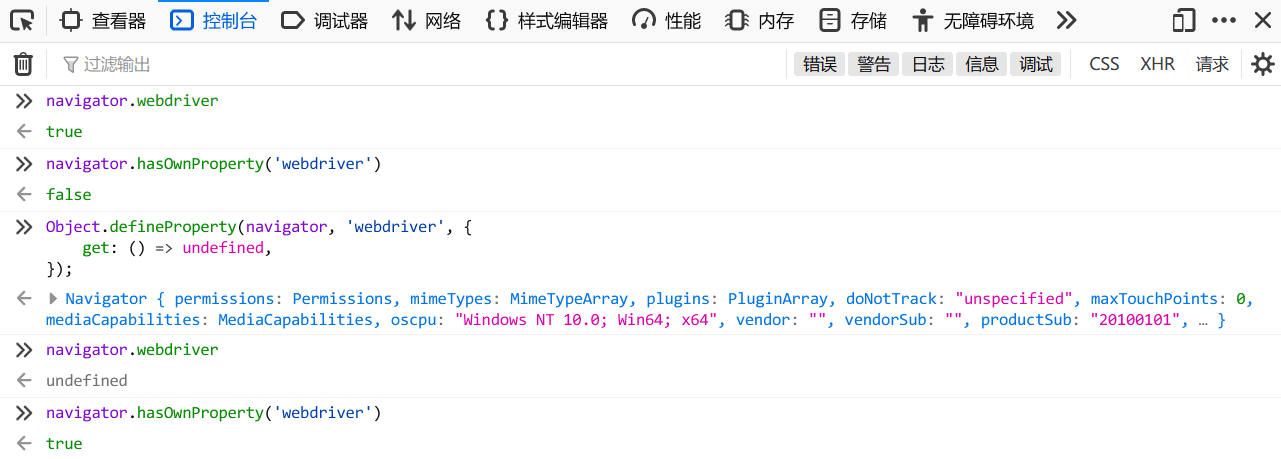
所以,另一种更好的做法是直接在原型链上把属性删除掉。
delete navigator.__proto__.webdriver;只是知道这一点还不够,虽然 Selenium 提供了执行任意 JavaScript 代码的功能,但当你有机会执行的时候整个页面已经加载和执行完了。
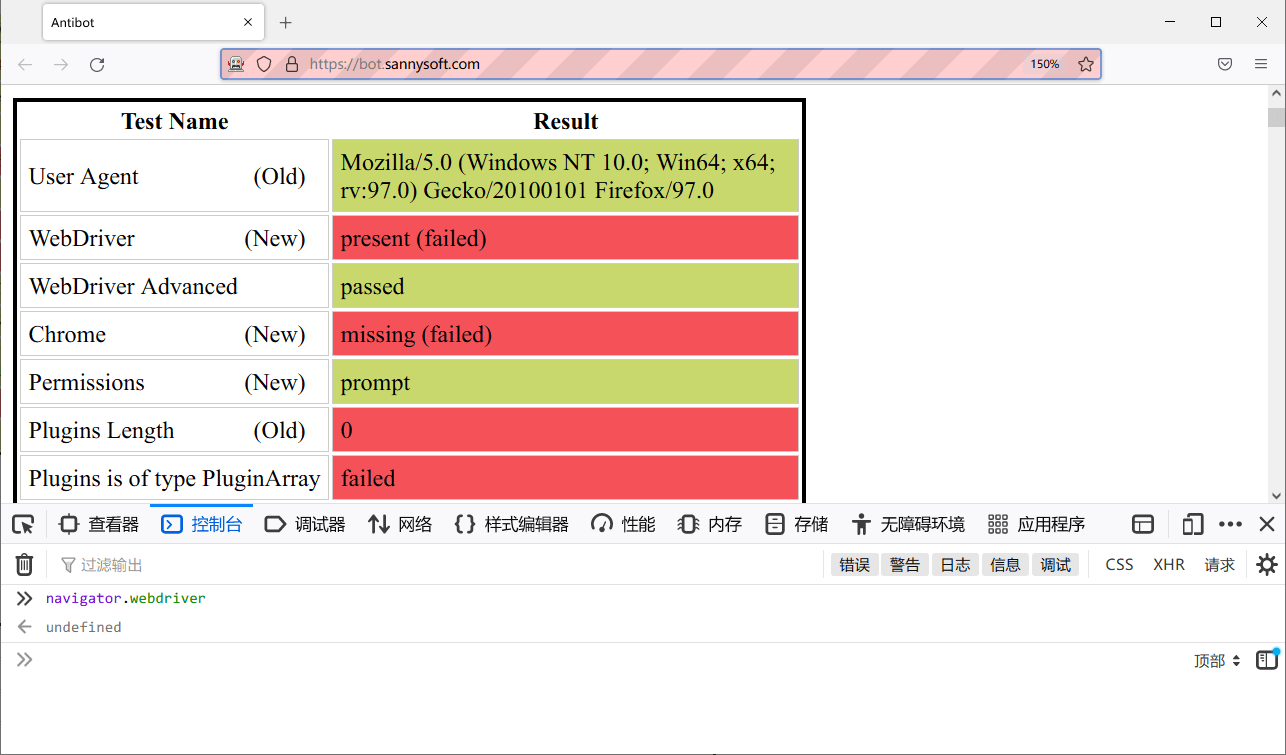
“Chrome”那一项检查的是 window.chrome,只有使用 Chrome 才会出现,因为现在使用的是 Firefox 所以没有这个属性是正常的。另外如果使用 Selenium 或 Puppeteer 调用 Chrome 的话 User-Agent 里会写上 HeadlessChrome 的字样从而被检查出来,不过把上面的 JS 代码稍微修改一下也可以很容易伪装。对于其他属性的检查结果也可以自行与非自动控制的浏览器对照。
看到那个“WebDriver: present (failed)”了吗?虽然现在去控制台检查可以发现伪装已经生效了,但是在加载页面的时候还没有执行伪装的 JS 代码,所以 navigator.webdriver 还是被检查出来了(实际的检查代码是 navigator.webdriver || _.has(navigator, "webdriver"),后者使用 Lodash 等效于使用 hasOwnProperty 检查)。所以现在的问题就变成了如何在页面加载前就运行伪装的 JS 代码,如果无法做到的话,那还是另请高明吧!无论如何,只要把 navigator.webdriver 处理成一个 falsy 的值就可以了。
已有的伪装方法
在 Google 上搜索了 1919 篇资料(大雾)后,我总结了几个目前已有的伪装方法,分别对应了上面的两种思路。
使用浏览器运行参数和配置进行伪装
在浏览器的启动参数里添加 --disable-blink-features=AutomationControlled,然后在配置的 excludeSwitches 添加 enable-automation,就可以隐藏 navigator.webdriver 了。
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=options)
driver.get("https://example.com")这几个参数和配置在网上广泛流传,但是这是 Chrome 限定的方法,因为我不使用 Chrome 所以没有实际测试过。Firefox 是不吃这一套的。
使用 Firefox 的话,需要把配置里的 dom.webdriver.enabled 设为 false:
from selenium import webdriver
profile = webdriver.FirefoxProfile()
profile.set_preference('dom.webdriver.enabled', False)
driver = webdriver.Firefox(firefox_profile=profile)遗憾的是,从 Firefox 88 开始,这个配置项也被移除了。navigator.webdriver 的值,最终还是要按照 W3C 的基本法,选举法……去产生,所以 Firefox 不会加入直接影响这些属性的方法(据说 Chrome 的那几个参数也被移除了)。
把 Firefox 的版本锁死在 87,并关闭自动更新,虽然可以解决问题,但是我们不能忘记某车务段拒绝将内部信息系统适配最新版本的操作系统而是死守旧版本结果闹出“人人都是高手”笑话的惨痛教训。我个人认为,在项目的初始阶段就重度依赖被废弃的功能并且为此固守旧版本,这是一种非常简单粗暴不负责任的解决方案。
使用 Chrome DevTools Protocol 执行 JS 代码
通过 Chrome DevTools Protocol 的命令就可以很容易地添加在打开网页前就会执行的 JS 代码了。
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'delete navigator.__proto__.webdriver',
})但是 Firefox 也不支持这种操作,毕竟这是 Chrome DevTools Protocol 而不是 Firefox DevTools Protocol……
那为什么不用 Chrome 呢?作为 Firefox 的忠实用户我怎么可能会这么做 ( ‘-‘ )ノ)`-‘ )
实际上是因为我不想为了调试这个就特地装一个 Chrome。虽然用 Selenium 的人一般都是用 Chrome,Firefox 在这方面似乎有点小众……
使用油猴脚本执行 JS
我们日常使用 Firefox、Chrome、Edge 这些现代浏览器的时候,一般都会安装许多实用的油猴脚本(如果你还没听说过油猴脚本的话,有必要进一步提高一下自己上网冲浪的水平)。油猴脚本本质上是一个 JS 文件,在打开特定网页时会自动运行,从而将自定义的功能加入到网页中。
默认情况下,油猴脚本会在 DOMContentLoaded 后运行,这个时候网页也已经加载完成了。通过在脚本前面的配置中添加 @run-at document-start 就可以使脚本在网页加载前运行,于是可以将上面的伪装用 JS 代码编写成一个简单的油猴脚本(这里还是使用修改 getter 的方法):
// ==UserScript==
// @name Hide navigator.webdriver
// @match *://*
// @run-at document-start
// ==/UserScript==
(() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
})();如果你日常使用的浏览器有安装运行油猴脚本的扩展的话,可以做一个小实验:添加上面的脚本,把 undefined 改为 true,再打开 https://bot.sannysoft.com/,就可以发现 navigator.webdriver 被成功地“反向”伪装了。
Selenium 控制的 Firefox 浏览器是可以添加扩展的,我们可以预先下载好 Tampermonkey 或 Violentmonkey 这两个油猴脚本扩展之一的 XPI 文件,然后在启动浏览器时加载。但是,如何使用 Selenium 在扩展中自动添加上面的油猴脚本,我暂时还没有找到什么简单的方法。已知的方法是自己在本地做一份安装了油猴脚本扩展及伪装脚本的 profile,然后在 Selenium 启动浏览器时读取,不过部署的时候如果还要把整个 profile 复制来复制去还是会比较麻烦。
简单优雅的解决方案:使用浏览器扩展在 Firefox 中完成伪装
虽然使用油猴脚本的方式比较麻烦,但它还是给我提供了一种思路。既然可以为浏览器添加扩展,我们可以自己编写一个简单的浏览器扩展来实现 navigator.webdriver 的伪装。之所以说这个方法简单优雅,是因为浏览器扩展是一个不会被轻易废弃的功能,而且我们实际上并不需要额外做很多复杂的工作。
Firefox 的扩展使用 XPI 的扩展名,本质上是一个 ZIP 格式的压缩包,方便起见也可以跳过这一步而是直接让浏览器从文件夹中加载扩展。不过开发 XPI 扩展的中文资料似乎不是很多,我直接简单参考了 MDN 上的浏览器扩展入门的“你的第一个扩展”章节,这里的知识对于快速了解基本概念来说已经足够了。
我们的浏览器扩展只需要包含记录扩展元数据的 manifest.json 和运行伪装代码的 main.js 而已。对于前者,只需要写上基本的信息就可以了:
{
"manifest_version": 2,
// 扩展的名称,在这里可以随意填写
"name": "webdriver-cleaner",
"version": "1.0",
// 由于我们需要在网页的运行环境下进行修改,因此需要使用内容脚本
"content_scripts": [
{
// 使脚本在网页加载前运行
"run_at": "document_start",
// 这个脚本会在打开所有网页时执行
// 也可以设定成<all_urls>
"matches": ["*://*/*"],
// 需要执行的JS文件,如果有多个则会按顺序执行
"js": ["main.js"]
}
]
}由于安全性上的考虑,扩展的运行环境和网页的运行环境是隔离的,不能直接互相修改和通信,具体可以参考MDN 上的这篇教程,不过我暂时还没完全看懂……正好有个经常使用的扩展“User-Agent Switcher”实现的是对 navigator.userAgent 的修改,我参考了它的修改部分的源代码写出了 main.js 的代码。核心部分还是只有那一行,由于环境隔离所以稍有修改:
delete window.navigator.wrappedJSObject.__proto__.webdriver;
console.log('navigator.webdriver cleaned:', window.navigator.wrappedJSObject.webdriver);在使用浏览器打开页面前,不要忘记加载这个扩展。正式发布的扩展需要进行签名,由于现在略过了这一步,所以扩展只能以临时的方式加载。加载的路径可以是扩展所在的文件夹或打包后的 XPI 文件的绝对路径,为了方便修改我就跳过打包过程了。
driver.install_addon(os.path.realpath('webdriver-cleaner'), temporary=True)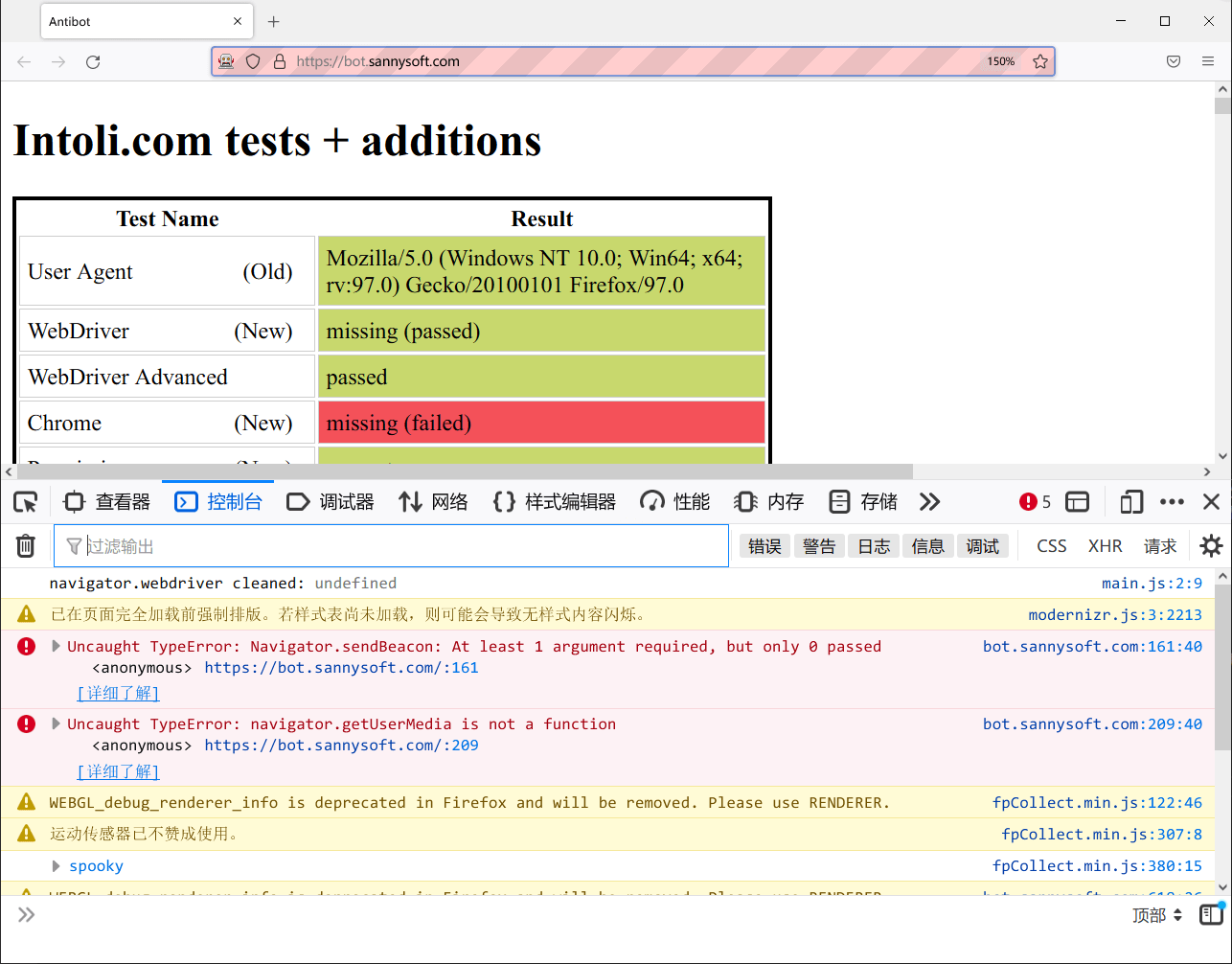
伪装并没有被发现……好耶!通过测试啦!(〃′▽`)
或许还可以换一个营销号浓度极高的标题:《爬虫必备!只需要一行代码,我再也不用害怕 Selenium Firefox 被发现啦!》
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2022/02/15/disable-geckodriver-detection-with-addon/