
封面图:Pixiv ID: 21022013 「お団子BZ サザビースタイル」 by たらやま
最近梯子挂了,去 Pixiv 找封面图就很麻烦……(;-_-)
背景
做匿名版的时候,当然也要实现敏感词过滤的功能。最直接的方法是把敏感词以数组的形式读取,然后使用 PHP 自带的函数 str_replace 全部替换掉,一般的网站都是用 * 来替换敏感词,不过小透明用的是“[数据删除]”……随便啦~ε-(•́ω•̀๑)
在 Google 上找了半天,找到了一个包括了大约三千四百个敏感词的词库,如果使用 str_replace 替换的话大概就得将查找替换执行大约三千四百遍,这个效率显然是非常低下的(摊手),因此有必要考虑一下优化的问题( • ̀ω•́ )✧
什么是 Trie 树(键树)
学习《数据结构》的时候,在“查找”这章看到过一个叫“键树”的结构(虽然学的时候这部分被跳过了,直接讲起了后面的哈希表……),也有把这种结构称为“字典树”、“Trie 树”的说法。
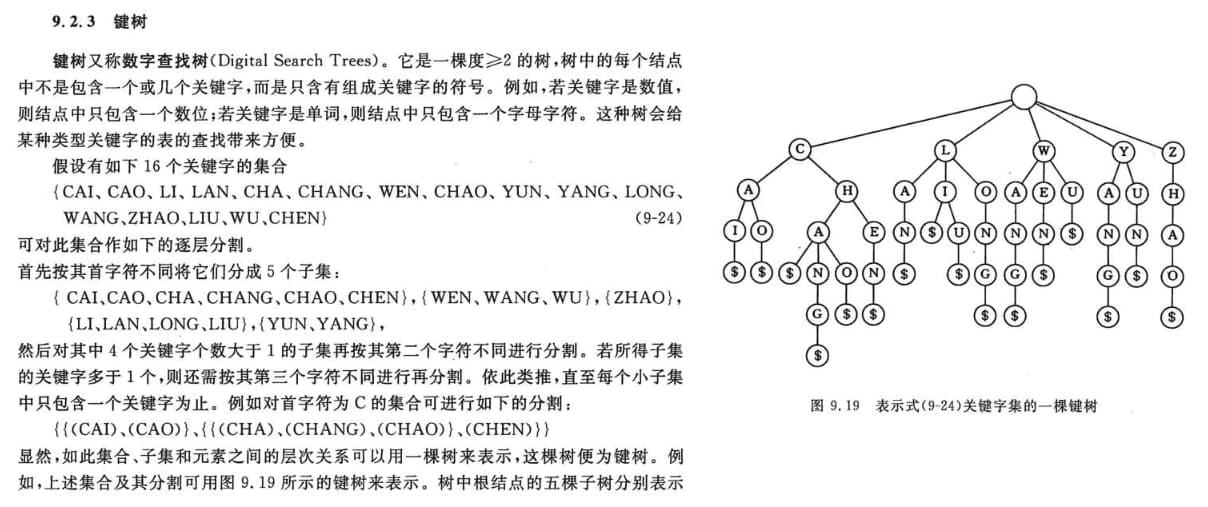
如图所示,键树将所有单词的每个字符作为一个节点,从根节点到叶子节点经过的边可以表示一个完整的单词。对于不同的单词,在键树中它们的相同的前缀可以被合并到一起,节省大量的查找时间。此外在文本中使用键树进行查找只需要遍历一次文本,消耗的时间只与文本长度有关,和单词数量无关,因此键树主要用于对大量的字符串进行操作。当然,单词数量会影响到键树占用的存储空间大小……用空间换时间,没关系啦!(´゚ω゚`)
一个使用键树的常见例子是搜索引擎的关键词提示:用户输入前几个字符,搜索引擎就会在后台根据一个非常大的词库给出补全的关键词提示。如果使用键树,就可以将查找范围限定在“php 是世界上”这几个字的子节点,而不需要将整个词库查找一遍,否则需要查找到什么时候呢?
使用关联数组保存键树
由于 PHP 有关联数组这个设定,因此很容易就可以想到使用关联数组的键作为键树的节点~
例如,对于用作敏感词库的,写入了以下内容的文本文件:
大傻子
大傻
傻子
贪污
贪污腐败对应的键树在 PHP 中通过以下的关联数组保存:
array(3) {
["大"]=> array(1) {
["傻"]=> array(2) {
["end"]=> bool(true)
["子"]=> array(1) {
["end"]=> bool(true)
}
}
}
["傻"]=> array(1) {
["子"]=> array(1) {
["end"]=> bool(true)
}
}
["贪"]=> array(1) {
["污"]=> array(2) {
["end"]=> bool(true)
["腐"]=> array(1) {
["败"]=> array(1) {
["end"]=> bool(true)
}
}
}
}
}在关联数组中放入键为 end 的项用来表示单词的结束。敏感词的第一个字可能是“大”、“傻”、“贪”,所以这个数组的第一层的三个键分别对应这三个字。“贪污”和“贪污腐败”共用“贪污”这个前缀,所以“污”字对应的数组里面有“腐”字,也有表示单词结束的 end 项。
生成键树
生成键树,以及后面的对文本进行扫描,都需要将文本拆成单个字符组成的数组。PHP 自带一个函数 str_split,不过它会将多字节的 Unicode 字符(例如汉字)也拆成字节,因此需要通过 preg_split 函数根据 Unicode 进行拆分:
function str_split_char($string) {
return preg_split("//u", $string, -1, PREG_SPLIT_NO_EMPTY);
}之后就可以按顺序遍历词库中每个单词的每个字符,在键树中添加对应的节点,其中有一个引用变量 $pointer 表示键树中当前指向的节点。
生成键树的演示视频和代码:
// $keywords 词库中每个单词组成的数组
function generate_replace_trie($keywords) {
$trie = [];
// 遍历所有单词
foreach ($keywords as $word) {
// 将单词中的字符拆成数组,先指向根节点
$chars = str_split_char($word);
$pointer = &$trie;
// 遍历所有字符
foreach ($chars as $char) {
// 如果字符对应的节点不存在,就新建一个
if (!isset($pointer[$char])) {
$pointer[$char] = [];
}
// 将指针指向字符对应的节点
$pointer = &$pointer[$char];
}
// 字符遍历完成后,在叶子节点添加end项,表示单词的结束
$pointer['end'] = true;
}
return $trie;
}生成的键树可以通过 JSON 格式保存到文件,之后要进行替换时再读取文件并解析,就可以省下重新生成键树的时间,提高效率~
使用键树进行查找和替换
查找的过程和建立键树一样:对于每个字符,需要走一条完整的从根节点到叶子节点的路径,因此也要设置一个引用变量 $pointer。
一开始的时候 $pointer 指向根节点,从头开始逐个扫描文本中的字符。如果根节点中存在以对应字符为键的子节点,说明可能找到了对应的单词,接下来就要继续扫描后面的字符,尝试确定单词的范围。扫描下一个字符的结果可以分为以下三种:
- 继续扫描
- 键树的词是 abc 和 abcd,输入的词是abcd。
- 已经扫描了 abc,d 在键树中存在,则继续扫描。
- 最终会找到 abcd,而不是 abc。
- 另一种情况:键树的词是 abc 和 abcde,输入的词是 abcd1。
- 已经扫描了 abc,abc 已经是一个完整的单词了,但是 d 在键树中也存在,所以还是要先保存 abc 的起止范围,然后继续扫描。
- 最终没有找到 abcde,所以根据前面保存的范围,可知找到的是 abc。
- 扫描完成
- 键树的词是 abc 和 de,输入的词是 abcd。
- 从 a 开始扫描到 abc,abc 已经是一个完整的单词了,而且 d 在键树中不存在,说明查找已经完成。
- 接下来就从上一个单词的最后一个字符 c 后面的 d 开始扫描,最终会找到 de。
- 匹配失败
- 键树的词是 abcd 和 bc,输入的词是 abc1。
- 从 a 开始扫描到 abc,但是 abc 不是单词,后面的 1 在键树中又不存在,说明匹配失败,直接结束扫描。
- 接下来就从上一个开始扫描的字符 a 后面的 b 开始扫描,最终会找到 bc。
每次找到单词时,都可以得到这个单词的下标范围。替换的时候将第一个字符改成替换词(不一定只有一个字符),剩下的字符设为空,最后用 implode 将字符拼回字符串就可以了。
查找和替换过程的演示视频和代码:
// $trie 刚刚生成的键树的关联数组
// $replace 用来替换单词的字符串
// $subject 需要进行替换的文本
// $count 保存替换的次数
// $list 保存替换过的单词
function str_replace_trie($trie, $replace, $subject, &$count = null, &$list = null) {
$count = 0;
$list = [];
// 从头开始,逐个扫描所有字符
$chars = str_split_char($subject);
for ($i = 0; $i < count($chars); $i++) {
// 将当前节点设为键树根节点
$pointer = &$trie;
// 如果这个字符是前缀的话,从这里继续往后,扫描单词的起止范围
if (isset($pointer[$chars[$i]])) {
// 先设定起止范围均为该字符
$index_start = $i;
$index_end = $i;
while ($index_end < count($chars)) {
// 指向这个字符的节点
$pointer = &$pointer[$chars[$index_end]];
$index_end++;
// 如果扫描过的部分已经是一个单词,则暂时保存最后一个字符的下标
if (isset($pointer['end'])) {
$index_end_found = $index_end - 1;
}
// 检查是否扫描完成或匹配失败(下一个字符在键树中不存在,扫描结束)
if (!isset($pointer[$chars[$index_end]])) {
// 之前的扫描是否已找到单词?(使用isset判断是否有记录最后一个字符的下标)
// 已找到就是扫描完成,进行替换
// 未找到就是匹配失败,什么都不做
if (isset($index_end_found)) {
// 清除暂时保存的下标
$index_end = $index_end_found;
unset($index_end_found);
// 第一个字符换成替换词,其他字符设为空,返回的时候拼回去
// 与此同时将替换的词记下来
$list_append = '';
for ($j = $index_start; $j <= $index_end; $j++) {
$list_append .= $chars[$j];
$chars[$j] = '';
}
$chars[$index_start] = $replace;
// 循环变量跳过单词部分,替换计数$count的值+1,在$list中添加这次替换的词
$i = $index_end;
$count++;
if (!in_array($list_append, $list)) {
$list[] = $list_append;
}
}
break;
}
}
}
}
return implode('', $chars);
}最后就是键树和 str_replace 的性能测试了~测试用的文本(test.txt)来自维基百科上国内某位领导人的词条中的个人生平部分,一万五千字左右,使用的词库(sensitive_word.txt)有大约三千四百个敏感词。除了对文本中的敏感词进行替换,还要进行计数,并记录下文本中出现了哪些敏感词。
使用 str_replace 的代码,将替换和记录敏感词的操作组合成了一个函数:
function replace_sensitiveword($string, $keywords, &$count = null, &$list = null) {
if ($list !== null) {
$list = [];
foreach ($keywords as $k) {
if (strpos($string, $k) !== false) $list[] = $k;
}
}
return str_replace($keywords, '<span style="color:red"">[数据删除]</span>', $string, $count);
}
$words = explode("\n", file_get_contents('sensitive_word.txt'));
$text = file_get_contents('test.txt');
$count = 0;
$list = [];
$start = microtime(true);
$replaced = replace_sensitiveword($text, $words, $count, $list);
$end = microtime(true);
$load_time = $end - $start;
echo nl2br($replaced);
echo '<br /><br />';
echo sprintf('字数:%d<br />敏感词数量:%d<br />替换时间:%ss<br />找到的敏感词(%d个):<br />', mb_strlen($text), $count, $exec_time, count($list));
echo implode(' ', $list);使用键树的代码:
function str_split_char($string) { ... }
function generate_replace_trie($keywords) { ... }
function str_replace_trie($trie, $replace, $subject, &$count = null, &$list = null) { ... }
// 生成键树并保存
// $words = explode("\n", file_get_contents('sensitive_word.txt'));
// $trie = generate_replace_trie($words);
// file_put_contents('sensitive_word_lite_trie.json', json_encode($trie, JSON_UNESCAPED_UNICODE));
$start = microtime(true);
$trie = json_decode(file_get_contents('sensitive_word_trie.json'), true);
$end = microtime(true);
$load_time = $end - $start;
$text = file_get_contents('test.txt');
$count = 0;
$list = [];
$start = microtime(true);
$replaced = str_replace_trie($trie, '<span style="color:red"">[数据删除]</span>', $text, $count, $list);
$end = microtime(true);
$exec_time = $end - $start;
echo nl2br($replaced);
echo '<br /><br />';
echo sprintf('字数:%d<br />敏感词数量:%d<br />读取词库时间:%ss<br />替换时间:%ss<br />总时间:%ss<br />找到的敏感词(%d个):<br />', mb_strlen($text), $count, $load_time, $exec_time, $load_time + $exec_time,count($list));
echo implode(' ', $list);看看结果:
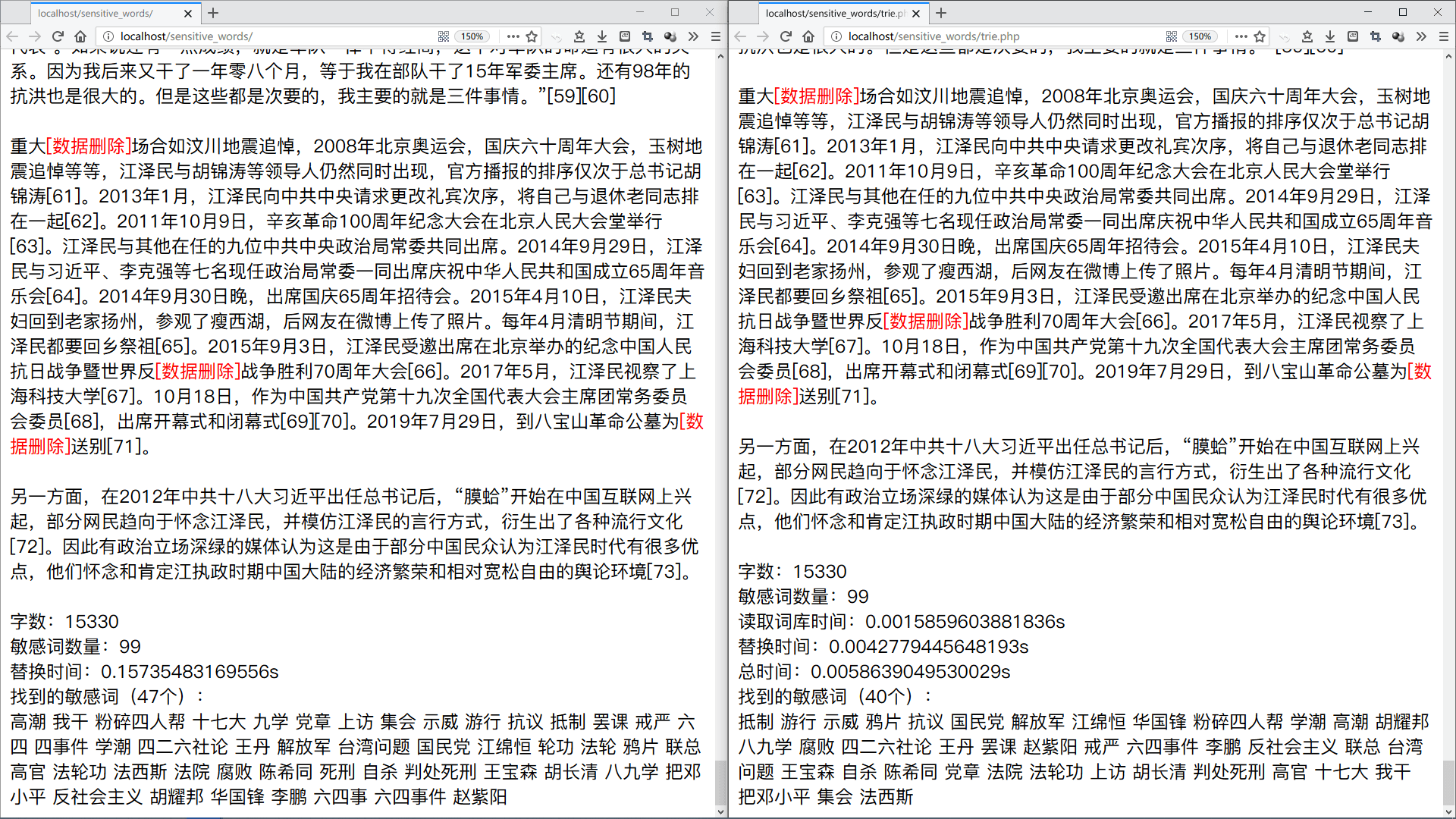
用这个测试的话就要上国庆的那啥名单了(逃
使用键树的性能提升是非常明显的~即使算上读取键树的时间(如果是从内存而不是硬盘读取键树的话,还可以更快一些),替换速度也达到了 str_replace 的 25 倍!
而且使用键树还修正了 str_replace 的一个小缺陷:
敏感词库中有一些敏感词是其他敏感词的前缀,这里使用一个相对来说不怎么敏感(?)的例子:“索尼”和“索尼大法”。如果文本中含有“索尼大法”,str_replace 会先查找“索尼”然后替换,这时文本就变成了“[数据删除]大法”,查找“索尼大法”的时候就找不到了,也就并没有把“索尼大法”这个敏感词完全过滤掉。如果是使用上面的键树,就可以保证即使找到了“索尼”也可以继续找到“索尼大法”(参见上面的“继续扫描”的情况),最终完整地过滤整个敏感词。
此外,由于键树是对逐个字符进行检查,因此还可以继续改进:如果当前扫描的字符是各种符号或生僻字的话,就直接跳过,扫描下一个字符。这样就可以应对在敏感词中间添加各种符号(例如:“敏*感*词”)以逃避检测的问题。很久以前有个叫“百度贴吧和谐测试器”的小工具就是这么处理敏感词的……
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2019/09/22/php-trie-replace-string/