
以前在某个 V 字头的技术论坛看过一个帖子,某君写了一个网页作为给女朋友的一百天礼物……当然写网页来表白/记录恋爱经历这种操作在 V 字头论坛已经被吐槽过不知道多少次了,不过这位某君的想法还是有点创意的——网页内容如下:
为了宣布“○○可爱”为一个合法成语,所以:请输入一个四字成语
我将自动为你接龙到“○○可爱”
或许你能找到那个帖子也说不定?
○○是某君的女朋友的昵称,总之这狗粮把我噎得……(=’_’=)
虽然现在我还没有女朋友啦……不过为了将来自己有女朋友的时候和一百天的时候做好准备实际上还是因为最近实在是太闲了,还是可以对它进行一些分析的~去掉狗粮的部分,它就变成了一个比较有意思的问题:给定起始和结束的成语,如何计算出这两个成语之间的一条接龙?
已经有不少提供在线成语接龙的网站了(比如这个),不过这些网站基本上都是允许用户设定一个起始成语,然后生成指定长度的接龙。只要不断地搜索“以○开头的成语”,就可以想接多少就接多少,总是能一直接下去的嘛!但是如果还要钦定结束的成语,那问题就变得不一样了。
问题的分析
成语接龙只考虑成语的第一个字和最后一个字的读音,这样的话每个成语实际上就是一条有向边,而所有的成语就组成了一张巨大的有向图。那相当于图的顶点的是什么呢?当然就是不同的读音啦!
这里设定成语接龙的规则是允许使用同音字。当然,即使要求必须使用相同的字,思路也是类似的。证明过程留作习题
给定起始和结束的成语,实际上我们在意的也只是起始成语的最后一个字和结束成语的第一个字的读音。以两个读音作为起点和终点,我们就成功地把成语接龙问题变成了一个“在图中求最短路径”的问题。

不过,要注意的是成语组成的图并不是有向无环图,有很多类似于“传宗接代 -> 代代相传”这种多条边组成一个环的情况(上面的示意图中也存在环),甚至还有“为所欲为”、“国将不国”这种一条边组成一个环的情况,在查找最短路径时需要避免出现这种环。
另外图中也存在一些只有入度没有出度的顶点,比如大家见了就想打的“一个顶俩”的 liǎ 就是完全接不下去的……等等这个好像不算成语吧?那还有“不置可否”、“东拼西凑”、“不尴不尬”……如果以这些作为起始成语的话,那就无解了 (•́ω•̀ ٥)
图的最短路径算法有很多,比如经典的 Dijkstra 和 Floyd 算法。不过这里的“图的最短路径问题”实际上是简化版的,每一条边之间并没有 cost 的区别,所以只要让路径经过尽可能少的边就可以了,于是我就选择了使用广度优先搜索来获取路径。
后面的代码都是使用 PHP 实现的,不过使用其他语言的话做法也是一样的啦……毕竟是比较简单的算法,也不需要用到别的第三方工具库 |•ω•`)
预处理数据
要折腾成语接龙,首先当然需要收集一个成语数据库。自己爬取的话还是太麻烦了啊……好在这种东西很容易找到现成的,我选择了 GitHub 上的 pwxcoo/chinese-xinhua 这个仓库,提供的数据是将三万多个成语的信息保存进一个数组的 JSON 文件:
[
{
"derivation": "语出《法华经·法师功德品》下至阿鼻地狱。”",
"example": "但也有少数意志薄弱的……逐步上当,终至堕入~。★《上饶集中营·炼狱杂记》",
"explanation": "阿鼻梵语的译音,意译为无间”,即痛苦无有间断之意。常用来比喻黑暗的社会和严酷的牢狱。又比喻无法摆脱的极其痛苦的境地。",
"pinyin": "ā bí dì yù",
"word": "阿鼻地狱",
"abbreviation": "abdy"
},
...
]每个成语的拼音都是使用空格分割的,所以很容易取出第一个字和最后一个字的拼音。不过我没有在后续的代码中直接使用这些拼音而是将它们用整数替代了(有点像是在使用枚举),和比较字符串相比,比较整数应该是更快的吧?
// 数据来自:
// https://github.com/pwxcoo/chinese-xinhua/blob/master/data/idiom.json
$idioms = json_decode(file_get_contents('idiom.json'), true);
$pinyins = [];
foreach ($idioms as &$idiom) {
$idiom['pinyin'] = str_replace([' ', ',', '?'], ' ', $idiom['pinyin']);
$pinyin = explode(' ', $idiom['pinyin']);
$idiom['start'] = $pinyin[0];
$idiom['end'] = $pinyin[count($pinyin) - 1];
if (!isset($pinyins[$idiom['start']])) $pinyins[$idiom['start']] = count($pinyins);
if (!isset($pinyins[$idiom['end']])) $pinyins[$idiom['end']] = count($pinyins);
// 后续使用$pinyins[$idiom['start']]和$pinyins[$idiom['end']]来保存首尾两字的读音
}为了简化代码和方便查找,这里就使用 SQLite 数据库来保存所有成语的信息:
CREATE TABLE `idioms` (
`id` INTEGER PRIMARY KEY,
`word` TEXT NOT NULL,
`pinyin` TEXT NOT NULL,
`explanation` TEXT NOT NULL,
`derivation` TEXT NOT NULL,
`example` TEXT NOT NULL,
`start` INTEGER NOT NULL,
`end` INTEGER NOT NULL
);
CREATE UNIQUE INDEX `idx_idioms_id` ON `idioms`(`id`);
CREATE INDEX `idx_idioms_word` ON `idioms`(`word`);
CREATE INDEX `idx_idioms_start` ON `idioms`(`start`)实际上只要保存自增 ID、成语本体和首尾两字读音就可以了,以及给经常用于查找的某几列添加索引。不过似乎写入得太慢了啊……一直到 PHP 默认的三十秒执行时间限制用完了也只写入了一两百个成语,按照三万多个成语的数据量来看不知道要写到什么时候。
这实际上和 SQLite 的运行原理有关。毕竟是不需要运行后台服务的使用单文件的数据库,修改数据实际上是写入文件,但是操作系统为了减少 IO 次数一般会先将读写的文件内容保存在缓存中,每隔一段时间再统一写入硬盘(在 Linux 下这个机制称为 sync)。为了保证对数据的每次修改都会确实地写入硬盘,SQLite 默认是每执行一个事务就等待一次 sync 操作,然后才会继续执行下一个,于是大部分时间就消耗在等待 sync 之中了,这个效率 efficiency 啊……要提速的话可以执行 PRAGMA synchronous = OFF(默认值是 FULL)禁止 SQLite 等待 sync,副作用是系统崩溃或意外断电时数据库会损坏。由于在使用预处理创建成语数据库之后也只是用于查找,并不需要修改数据,所以这么设定是没问题的。
另外 SQLite 默认会在执行事务时创建一个 db-journal 文件用于事务的回滚,不过每次插入成语数据时都要写入这东西也够麻烦的……而且确实也不需要回滚,所以使用 PRAGMA journal_mode = MEMORY 把它放到内存里。如此操作之后,所有成语的数据就可以在两秒之内写入数据库啦!( ︠ु ௰︡ू)
构建遍历树和使用广度优先搜索
对数据进行预处理之后,就需要考虑如何找到最短路径了。之前提过我选择使用广度优先搜索算法求解,在求解过程中需要从成语的图中产生一个遍历树。以“身经百战 -> 栈山航海 -> 海外奇谈 -> 谈笑风生”这条接龙为例,对应的遍历树如图所示:

- 遍历树中的每个节点表示一个成语和它的尾字读音
- 产生子节点,也就是根据当前节点的尾字读音,查找以这个读音开头的成语
- 如果某个节点的尾字读音和给定的结束成语的首字读音相同,说明成功地找到了一个解,遍历结束
这里使用一个类来表示遍历树的节点,在搜索的时候都是使用数据库中的 ID 来表示成语,并不需要考虑成语的其他信息:
class IdiomSearchNode {
public ?IdiomSearchNode $parent;
public int $id;
public int $end;
public SQLite3 $db;
public function __construct(?IdiomSearchNode $parent, int $id, SQLite3 $db) {
$this->parent = $parent;
$this->id = $id;
$this->db = $db;
// 获取当前节点的成语的尾字读音
$statement = $db->prepare('SELECT `end` FROM `idioms` WHERE `id` = :0 LIMIT 1');
$statement->bindValue(':0', $this->id, SQLITE3_INTEGER);
$row = $statement->execute()->fetchArray(MYSQLI_ASSOC);
if (!$row) throw new Exception('Invalid idiom');
$this->end = $row['end'];
}
/** @return IdiomSearchNode[] */
public function getChildren(array &$set) {
// 查找以尾字读音开头的成语
$statement = $this->db->prepare('SELECT `id` FROM `idioms` WHERE `start` = :0');
$statement->bindValue(':0', $this->end, SQLITE3_INTEGER);
$execute = $statement->execute();
$result = [];
while ($row = $execute->fetchArray(SQLITE3_ASSOC)) {
// $set的作用稍后会提及
if (isset($set[$row['id']])) continue;
$set[$row['id']] = true;
$result[] = new IdiomSearchNode($this, $row['id'], $this->db);
}
return $result;
}
}广度优先搜索一般都是使用队列的方式实现的。以上面的遍历树示意图为例,在求解时遍历和产生子节点的顺序如下:
- 初始化队列,加入根节点“身经百战”
- 取出“身经百战”,找到以 zhàn 开始的成语“战火纷飞”、“栈山航海”、“战战兢兢”……依次加入队列
- 取出“战火纷飞”,找到以 feī 开始的成语“飞蛾扑火”,加入队列
- 取出“栈山航海”,找到以 hǎi 开始的成语“海市蜃楼”、“海外奇谈”……依次加入队列
- 此时可以注意到,“海外奇谈”已经可以接上给定的结束成语“谈笑风生”了,所以结束遍历
- 从“海外奇谈”开始往上回溯父节点“栈山航海”和“身经百战”,再把结束成语“谈笑风生”加上,由此就可以构造出“身经百战 -> 栈山航海 -> 海外奇谈 -> 谈笑风生”这个解
前面也提过,在图中查找最短路径时,要避免路径产生环而出现死循环,所以需要将已经遍历过的成语保存到一个集合中,在将成语加入队列前要检查这个成语之前是否已经遍历过(集合中是否已有该成语)。PHP 中并没有集合的数据结构啊……不过,根据以下的一些事实:
- PHP 的数组的底层实现,实际上就是插入和查找的时间复杂度为常数阶的哈希表(参见这里)
- 使用
isset($arr[$item])比in_array($item, $arr)和array_key_exists($item, $arr)更快(参见这里)
因为这里只需要考虑整型的成语 ID,因此完全可以使用一个数组来模拟实现集合,向集合中加入元素就是将数组中成语 ID 的 key 对应的值设为任意 null 之外的值,使用 isset 判断集合中是否存在某元素。
使用广度优先搜索来搜索路径的完整代码如下:
$idiomDb = new SQLite3('idioms.db');
// 保存成语ID的集合
$set = [];
// 搜索时使用的队列
$queue = new SplQueue;
// 在数据库中查找给定的起始和结束的成语
$statement = $idiomDb->prepare('SELECT * FROM `idioms` WHERE `word` = :0');
$statement->bindValue(':0', $_POST['start'], SQLITE3_TEXT);
$idiomStart = $statement->execute()->fetchArray(SQLITE3_ASSOC);
$statement->bindValue(':0', $_POST['end'], SQLITE3_TEXT);
$idiomEnd = $statement->execute()->fetchArray(SQLITE3_ASSOC);
if (!$idiomStart || !$idiomEnd) throw new Exception('Invalid idiom');
// 从起始成语开始创建第一个要遍历的节点
$queue->enqueue(new IdiomSearchNode(null, $idiomStart['id'], $idiomDb));
$set[$idiomStart['id']] = true;
$set[$idiomEnd['id']] = true;
// 循环从队列中取出和加入节点进行广度优先遍历,一直遍历到找到解或无解为止
$found = null;
while (!$queue->isEmpty() && !$found) {
/** @var IdiomSearchNode */
$node = $queue->dequeue();
$children = $node->getChildren($set);
// 打乱子节点的顺序,稍后说明作用
shuffle($children);
foreach ($children as $child) {
// 如果有可以接上结束成语的子节点就结束遍历,否则加入队列
if ($child->end === $idiomEnd['start']) {
$found = $child;
break;
}
$queue->enqueue($child);
}
}有些成语之间最短的接龙是不唯一的,但是按照以上流程只会得到固定的一个解。如果将算法随机化,也就是在遍历节点时将它产生的子节点随机打乱顺序再加入队列,每次运行算法就有可能得到不同的解了。
还是使用上面的从“身经百战”接到“谈笑风生”作为例子,除了“身经百战 -> 栈山航海 -> 海外奇谈 -> 谈笑风生”之外,还有“身经百战 -> 战战兢兢 -> 经验之谈 -> 谈笑风生”的解法。按照默认顺序会先遍历到“栈山航海”,然后发现子节点中的“海外奇谈”可以接到结束成语,由此得到第一个解。但是打乱的话就有可能先遍历到“战战兢兢”,从而得到第二个解。
搜索结束后就可以通过回溯的方式来构造解,在构造解的时候还可以一并读取成语的其它信息:
$result = [];
if ($solve = (bool)$found) {
unset($idiomEnd['id']);
unset($idiomEnd['start']);
unset($idiomEnd['end']);
array_unshift($result, $idiomEnd);
$statement = $idiomDb->prepare('
SELECT
`word`, `pinyin`, `explanation`,
`derivation`, `example`
FROM `idioms`
WHERE `id` = :0
LIMIT 1
');
while ($found) {
$statement->bindValue(':0', $found->id);
array_unshift($result, $statement->execute()->fetchArray(SQLITE3_ASSOC));
$found = $found->parent;
}
}成品和一些结论
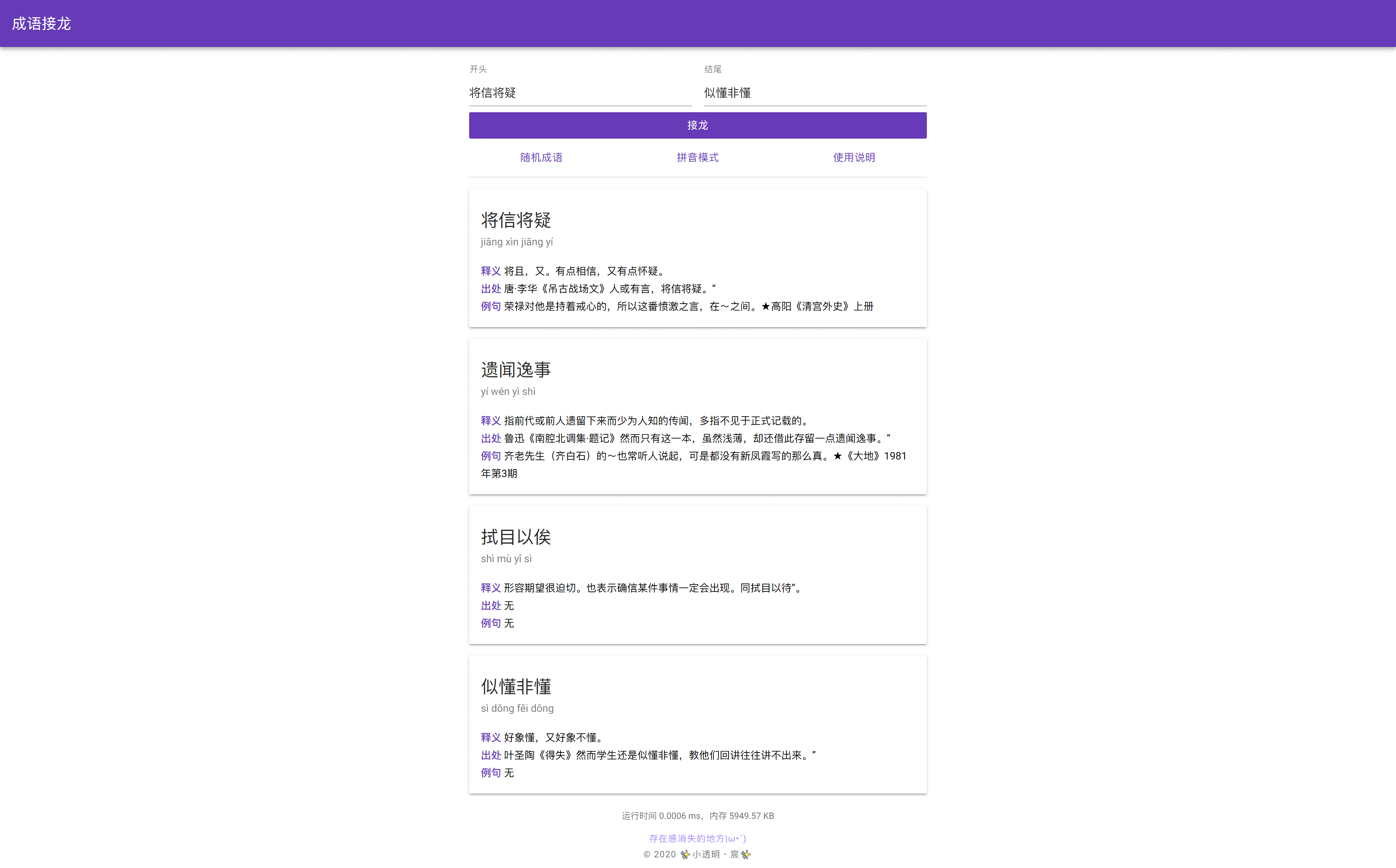
你可以前往 https://i.akarin.dev/idioms-solitaire/ 亲自体验一下~(*′ ▽‘)
除了支持输入起始和结束的成语进行接龙,也可以直接输入起始和结束的拼音。比如你可以来一条可以接到 yí 的接龙,这样就可以在和别人玩接龙的时候把对方的任意成语都接到“一个顶俩”然后被对方真人快打。也可以像 V 字头论坛的某君一样接到“○○可爱”上,嗯……用这个发狗粮是没关系的。
当然直接输入“一个顶俩”是不行的,因为它并没有被收录到我使用的成语数据库中。
随机取两个成语进行接龙的话,得到的最短接龙长度(包括起始和结束的成语)都在 3 到 5 之间。在平均情况下,每次运行这个算法时一般只需要遍历一二十个甚至个位数的节点,内存占用不超过 800 KB,运行时间不超过 10 ms。我测试时碰到的最坏情况是从“方寸已乱”接到“操觚染翰”,接龙长度为 5,求解时需要遍历的节点数从 25 到 550 个不等(由于将算法随机化了,所以每次运行时遍历的节点数会有区别),在遍历节点最多的最坏情况下内存占用 3 MB,运行时间 200 ms,可以说这个算法运行起来还是相当快的。
有没有办法再快一点呢?因为求解的过程中“查找以○开头的成语”这个操作执行得非常频繁,完全可以不使用 SQL 语句来查找,而是预先准备好一张记录了每个拼音对应的以该拼音开头的所有成语 ID 的表,在产生子节点的时候直接查表就可以了。根据我自己的测试,使用查表法可以使平均情况下的运行时间再降低一个数量级,但是这个表本身会占用 5 MB 的内存,典型的空间换时间 (′゜ω。‵)
封面图:Pixiv ID: 66567478 「HAPPYNEWYEAR 2018」 by チノマロン
不过因为现在已经是 2021 年了,我就自己把图上的“HappyNewYear 2018”去掉了。
更新一个使用 JavaScript 的实现,你可以将这里的代码粘贴到浏览器的控制台,然后随意尝试~
- 直接使用 jsDelivr 的 CDN 从上面提到的 GitHub 仓库在线加载成语数据,大约需要消耗流量 3.5 MB
- 未对拼音创建枚举,因此使用的是直接比较字符串是否相等
- 未打乱子节点,因此得到的接龙是固定的
- 执行时会在控制台中输出遍历的节点数和运行时间,不过没有统计内存占用情况
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。不允许内容农场类网站、CSDN 用户和微信公众号转载。
本文作者:✨小透明・宸✨
本文链接:https://akarin.dev/2021/01/28/idioms-solitaire/